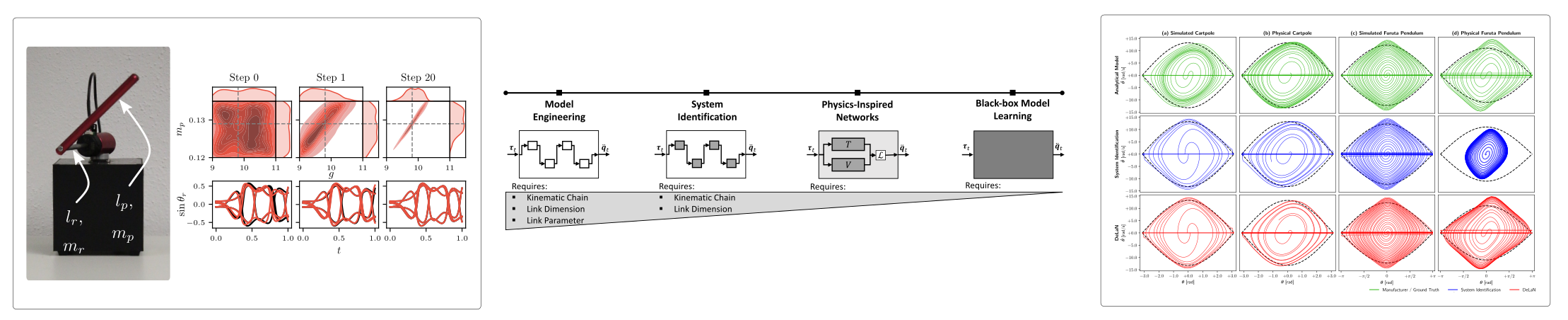
Physics-Inspired Learning 
Incorporating physics-based inductive biases into robot reinforcement learning marks a significant leap towards more efficient and robust robotic systems. By embedding differentiable physics models directly into the learning process, robots can develop an intuitive understanding of physical laws, leading to more natural and adaptive behaviors. This approach allows for the backpropagation of gradients through physical equations, enabling robots to refine their predictions and control strategies in a way that's consistent with how the real world operates. Additionally, employing techniques like domain randomization exposes the learning algorithm to a wide variety of simulated scenarios, fostering a robustness that can translate to better performance in unpredictable real-world environments. Furthermore, simulation-based inference acts as a powerful tool, allowing robots to infer the underlying physical properties of their environment, which in turn informs and enhances their decision-making process. Together, these physics-informed strategies are setting a new standard for how robots learn and interact with their surroundings, promising more adaptable, efficient, and intelligent machines.
Differentiable Physics 
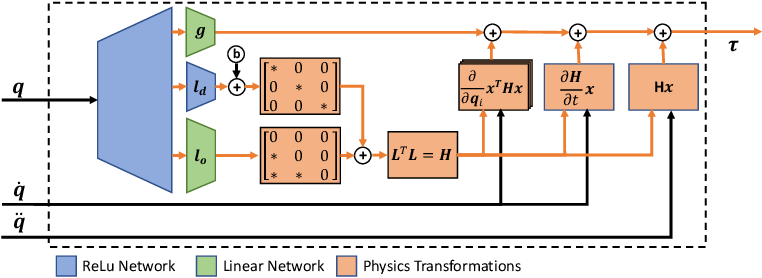
In order to effectively integrate physics knowledge into our machine learning models, differentiability is a key property. We are exploring how these models can be used to incorporate structured knowledge into robot learning for both system identification and model-based reinforcement learning.
- Schulze, L.; Negri, J.D.; Barasuol, V.; Medeiros, V.S.; Becker, M.; Peters, J.; Arenz, O. (2026). Floating-Base Deep Lagrangian Networks, IEEE International Conference on Robotics and Automation (ICRA).
- Schulze, L.; Peters, J.; Arenz, O. (2025). Context-Aware Deep Lagrangian Networks for Model Predictive Control, 2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS).
- Lutter, M.; Peters, J. (2023). Combining Physics and Deep Learning to learn Continuous-Time Dynamics Models, International Journal of Robotics Research (IJRR), 42, 3.
- Watson, J.; Hanher, B.; Peters, J. (2022). Differentiable Simulators as Gaussian Processes, R:SS Workshop: Differentiable Simulation for Robotics.
- Lutter, M.; Ritter, C.; Peters, J. (2019). Deep Lagrangian Networks: Using Physics as Model Prior for Deep Learning, International Conference on Learning Representations (ICLR).
Domain Randomization
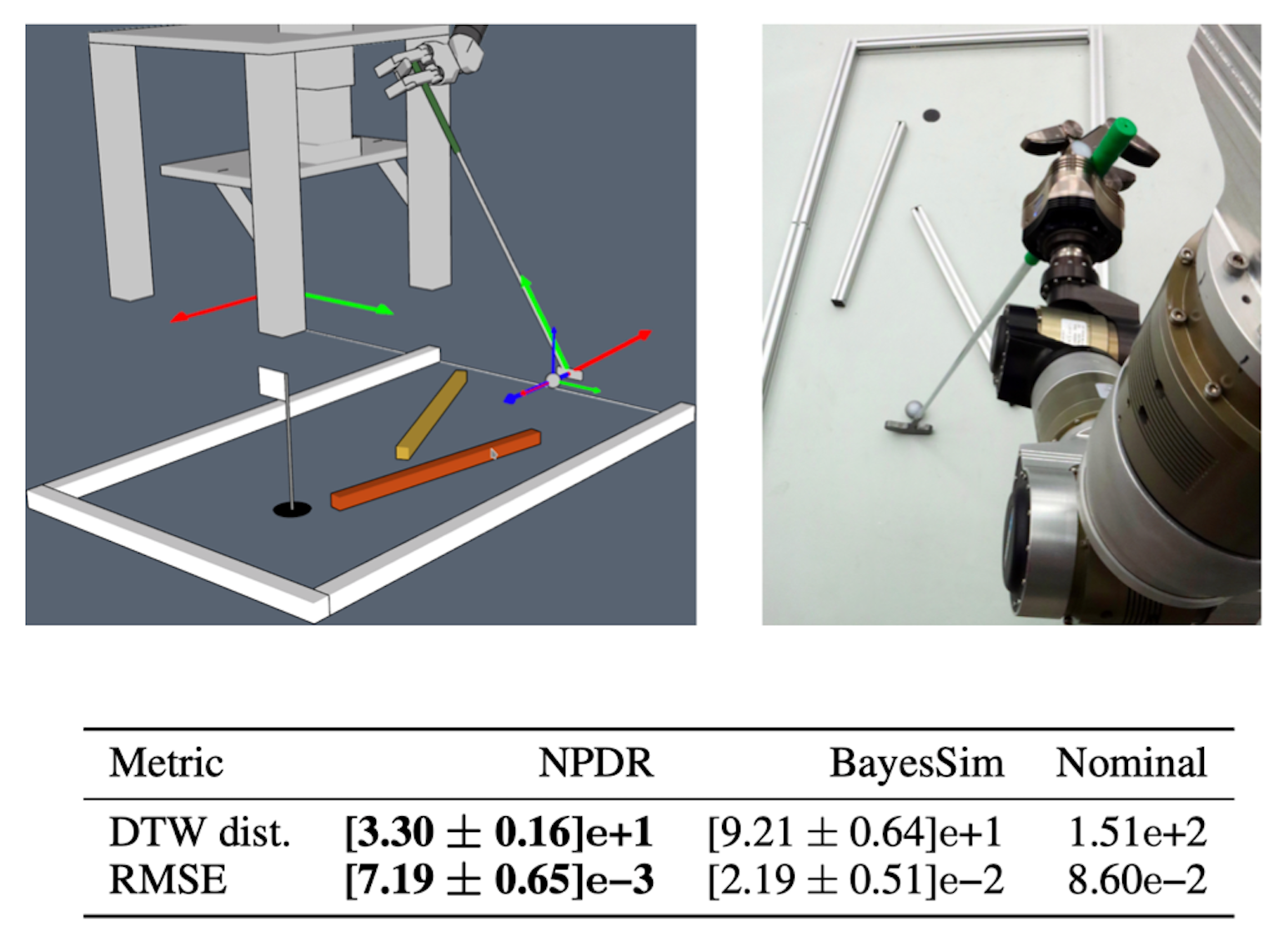
Neural Posterior Domain Randomization. Combining domain randomization and reinforcement learning is a widely used approach to obtain control policies that can bridge the gap between simulation and reality. However, existing methods make limiting assumptions on the form of the domain parameter distribution which prevents them from utilizing the full power of domain randomization. Typically, a restricted family of probability distributions (eg, normal or uniform) is chosen a priori for every parameter. Furthermore, straightforward approaches based on deep learning require differentiable simulators, which are either not available or can only simulate a limited class of systems. Such rigid assumptions diminish the applicability of domain randomization in robotics. Building upon recently proposed neural likelihood-free inference methods, we introduce Neural Posterior Domain Randomization (NPDR), an algorithm that alternates between learning a policy from a randomized simulator and adapting the posterior distribution over the simulator’s parameters in a Bayesian fashion. Our approach only requires a parameterized simulator, coarse prior ranges, a policy (optionally with optimization routine), and a small set of real-world observations. Most importantly, the domain parameter distribution is not restricted to a specific family, parameters can be correlated, and the simulator does not have to be differentiable. We show that the presented method is able to efficiently adapt the posterior over the domain parameters to closer match the observed dynamics. Moreover, we demonstrate that NPDR can learn transferable policies using fewer real-world rollouts than comparable algorithms.
- Muratore, F.; Gruner, T.; Wiese, F.; Belousov, B.; Gienger, M.; Peters, J. (2021). Neural Posterior Domain Randomization, Conference on Robot Learning (CoRL).