
Currently Available Theses Topics
We offer these current topics directly for Bachelor and Master students at TU Darmstadt who can feel free to DIRECTLY contact the thesis advisor if you are interested in one of these topics. Excellent external students from another university may be accepted but are required to first email Jan Peters before contacting any other lab member for a thesis topic and upload your ☞ CV and transcripts. Note that we cannot provide funding for any of these theses projects.
We highly recommend that you do either our robotics and machine learning lectures (Robot Learning, Statistical Machine Learning) or our colleagues (Grundlagen der Robotik, Probabilistic Graphical Models and/or Deep Learning). Furthermore, we strongly recommend that you take both Robot Learning: Integrated Project, Part 1 (Literature Review and Simulation Studies) and Part 2 (Evaluation and Submission to a Conference) before doing a thesis with us.
In addition, we are usually happy to devise new topics on request to suit the abilities of excellent students. Please DIRECTLY contact the thesis advisor if you are interested in one of these topics. When you contact the advisor, it would be nice if you could mention (1) WHY you are interested in the topic (dreams, parts of the problem, etc), and (2) WHAT makes you special for the projects (e.g., class work, project experience, special programming or math skills, prior work, etc.). Supplementary materials (CV, grades, etc) are highly appreciated. Of course, such materials are not mandatory but they help the advisor to see whether the topic is too easy, just about right or too hard for you.
Only contact *ONE* potential advisor at the same time! If you contact a second one without first concluding discussions with the first advisor (i.e., decide for or against the thesis with her or him), we may not consider you at all. Only if you are super excited for at most two topics send an email to both supervisors, so that the supervisors are aware of the additional interest.
FOR FB16+FB18 STUDENTS: Students from other depts at TU Darmstadt (e.g., ME, EE, IST), you need an additional formal supervisor who officially issues the topic. Please do not try to arrange your home dept advisor by yourself but let the supervising IAS member get in touch with that person instead. Multiple professors from other depts (some people in FB16+18 are old-fashioned) have complained that they were asked to co-supervise before getting contacted by our advising lab member.
NEW THESES START HERE
Ditch your network: reducing the neural network’s influence in temporal-difference learning methods.
Scope: Master's thesis
Advisors: Theo Vincent
Added: 2026-05-18
Start: ASAP
Topic: 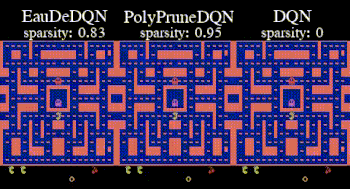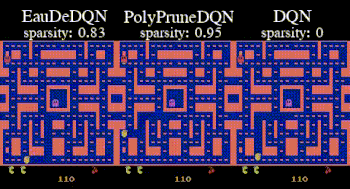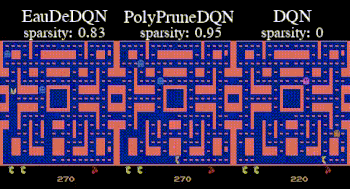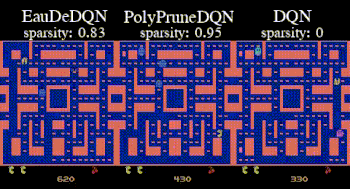 Temporal-difference (TD) learning is at the heart of reinforcement learning (RL). It is a key component of RL methods that have outperformed humans on some complex tasks [1]. In robotics, actor-critic methods rely on TD learning to train the critic [2]. In recent years, most attention has been paid to scaling up the neural network used in TD learning [3]. In this thesis, we propose another path that reduces the reliance on neural networks to limit their negative influence [4]. The student will first investigate this idea on simple problems before comparing its performance with strong baselines in complex environments. Depending on the result, the student might also train robotic policies in the MuJoCo simulator. The student will be welcome to propose some ideas as well.
Temporal-difference (TD) learning is at the heart of reinforcement learning (RL). It is a key component of RL methods that have outperformed humans on some complex tasks [1]. In robotics, actor-critic methods rely on TD learning to train the critic [2]. In recent years, most attention has been paid to scaling up the neural network used in TD learning [3]. In this thesis, we propose another path that reduces the reliance on neural networks to limit their negative influence [4]. The student will first investigate this idea on simple problems before comparing its performance with strong baselines in complex environments. Depending on the result, the student might also train robotic policies in the MuJoCo simulator. The student will be welcome to propose some ideas as well.
Highly motivated students can apply by emailing theovincentjourdat@gmail.com. Please attach your CV and clearly state why you are interested in this topic.
Requirements:
- Strong Python programming skills
- Knowledge in Reinforcement Learning
- Experience with deep learning libraries
References:
[1] Silver, D., et al. "Mastering the game of Go with deep neural networks and tree search." Nature 2016.
[2] Haarnoja, T., et al. "Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor." ICML 2018.
[3] Chen, L., et al. "Decision transformer: Reinforcement learning via sequence modeling." NeurIPS 2021.
[4] Van Hasselt, H. et al. "Deep reinforcement learning and the deadly triad." arXiv 2018.
Gradient-Free Spiking Policy Learning for Neuromorphic Robotic Control via Optimal Transport
Scope: Master's thesis
Advisors: An Thai Le, Jan Peters
Added: 2026-05-12
Start: ASAP
Topic: 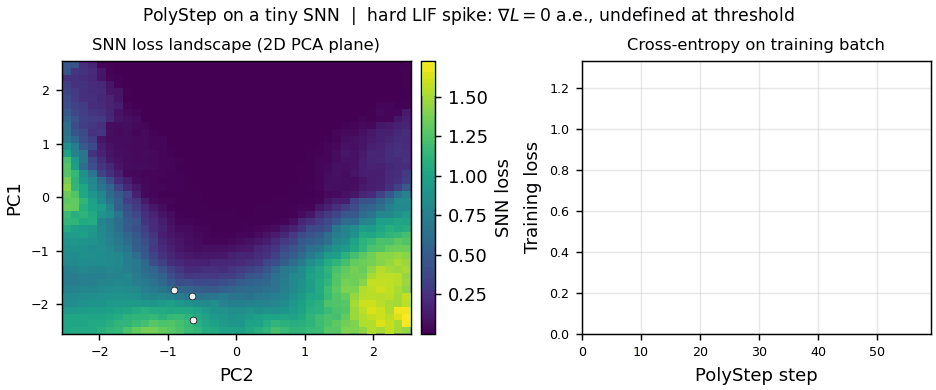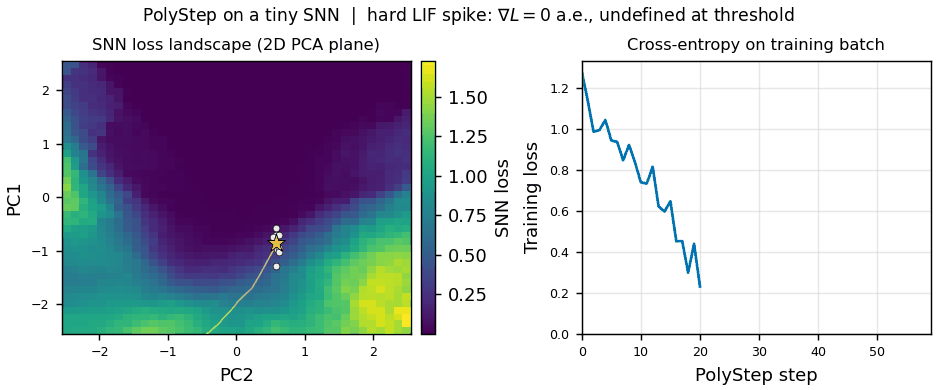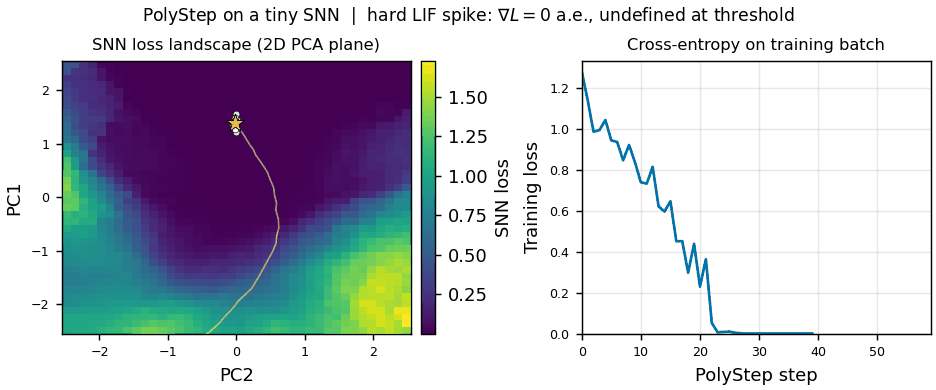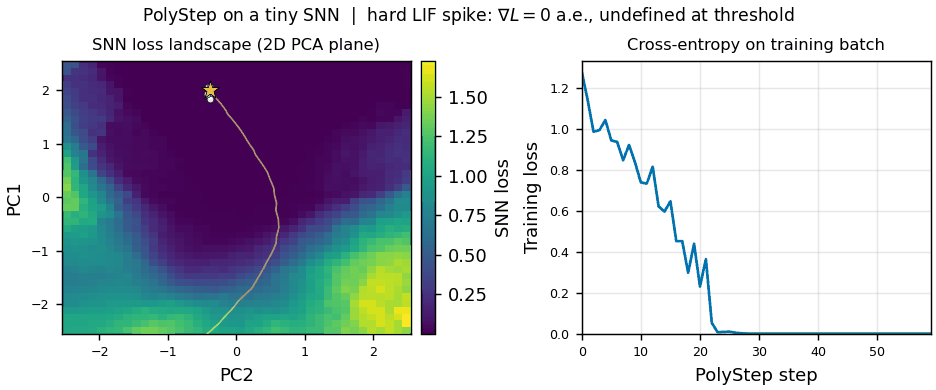 This thesis is a collaboration between IAS and VinUni Center for AI Research.
This thesis is a collaboration between IAS and VinUni Center for AI Research.
Spiking Neural Networks (SNNs) are emerging as the computational backbone for energy-efficient robotic autonomy: they process event-driven sensor data (e.g., DVS cameras, neuromorphic tactile sensors) natively, run on milliwatt-scale neuromorphic hardware (Intel Loihi 2, BrainChip Akida), and offer microsecond-level inference latency - properties that are critical for reactive robotic control [1, 2]. However, training SNN controllers remains a fundamental bottleneck: the hard threshold (Heaviside) of Leaky Integrate-and-Fire (LIF) neurons has zero gradient almost everywhere, forcing the entire field to rely on the Surrogate Gradient (SG) hack - a biased approximation whose slope requires per-task tuning, suffers from vanishing/exploding gradients in deep architectures, and demands full Backpropagation Through Time (BPTT) across all simulation timesteps, consuming memory that scales linearly with the temporal horizon [3, 4].
PolyStep [5] is a recently introduced gradient-free optimizer based on Entropic Optimal Transport that eliminates this bottleneck. Instead of differentiating through spiking dynamics, PolyStep evaluates the SNN purely via forward passes at structured polytope vertices in a compressed parameter subspace, then computes softmax-weighted barycentric projections to find descent directions. On MNIST, PolyStep already achieves 93.4% accuracy with hard-LIF SNNs, without any surrogate gradients, while using 29.8x less memory than BPTT at temporal horizons of T=400 [5].
This thesis investigates the first application of PolyStep to spiking policy learning for robotic control, targeting two challenge domains:
(1) Event-Driven Locomotion: Train an SNN-based locomotion controller for a simulated quadruped (e.g., Unitree Go1 in MuJoCo), where the policy processes proprioceptive spikes and produces joint torques via a recurrent LIF network. The hard spike threshold makes the policy non-differentiable end-to-end; standard RL pipelines (PPO, SAC) require surrogate gradients for the SNN backbone, while PolyStep can optimize the policy directly against cumulative reward as a blackbox objective.
(2) Tactile Spike-Based Manipulation: Leverage event-driven tactile sensors (e.g., EveTac [6]) to learn a reactive grasping/insertion policy. The SNN receives asynchronous spike streams from tactile events and outputs motor commands. Here, both the spike encoding and the contact dynamics introduce cascading non-differentiabilities that compound the surrogate gradient problem.
The thesis will benchmark PolyStep against surrogate-gradient BPTT (using snnTorch [7]) and gradient-free baselines (CMA-ES, OpenAI-ES) on these tasks, analyzing: (a) final policy performance, (b) memory efficiency across temporal horizons, (c) sensitivity to surrogate slope tuning (which PolyStep eliminates), and (d) sim-to-real transferability of the trained policies to physical hardware.
Content:
- Literature review on SNN training for robotic control (surrogate gradients, evolutionary methods, BPTT alternatives)
- Implementation of SNN locomotion policies in MuJoCo, trained with PolyStep
- Implementation of SNN tactile manipulation policies with event-driven sensing
- Comparative benchmarking against surrogate-gradient BPTT and gradient-free baselines (CMA-ES, OpenAI-ES)
- Analysis of memory scaling, hyperparameter sensitivity, and sim-to-real transfer potential
- Optional: deployment on neuromorphic hardware (Intel Loihi 2) for closed-loop control
Requirements:
- Ongoing master's studies in Robotics, Machine Learning, or Computer Science
- Strong background in reinforcement learning and neural network training
- Experience with Python, PyTorch, and MuJoCo
- Familiarity with spiking neural networks or willingness to learn quickly
- Interest in neuromorphic computing and event-driven robotics
References:
- [1] Sandamirskaya, Y. et al. "Neuromorphic computing hardware and neural architectures for robotics." Science Robotics 7, eabl8419 (2022).
- [2] Vitale, A. et al. "Event-driven vision and control for UAVs on a neuromorphic chip." ICRA 2021.
- [3] Neftci, E. O., Mostafa, H. & Zenke, F. "Surrogate gradient learning in spiking neural networks." IEEE Signal Processing Magazine 36, 51–63 (2019).
- [4] Zenke, F. & Vogels, T. P. "The remarkable robustness of surrogate gradient learning for instilling complex function in spiking neural networks." Neural Computation 33, 899–925 (2021).
- [5] Le, A. T. "Training Non-Differentiable Networks via Optimal Transport." arXiv:2605.01928 (2026).
- [6] Funk, N., Helmut, E., Chalvatzaki, G., Calandra, R. & Peters, J. "Evetac: An Event-Based Optical Tactile Sensor for Robotic Manipulation." IEEE Transactions on Robotics 40, 3812–3832 (2024).
- [7] Eshraghian, J. K. et al. "Training spiking neural networks using lessons from deep learning." Proceedings of the IEEE 111, 1016–1054 (2023).
Apply to an@robot-learning.de with your CV, transcript of records, and a short paragraph on why you are interested in the topic.
Robotic Assembly of Modular Architectural Systems
Scope: Master’s thesis
Advisors: Joao Carvalho, Yuxi Liu
Added: 2026-04-13
Start: ASAP
Topic:  This thesis is a collaboration between IAS, DDU, and DFKI, and bridges architectural design, digital fabrication, and robotics, thereby enabling scalable, flexible construction workflows.
This thesis is a collaboration between IAS, DDU, and DFKI, and bridges architectural design, digital fabrication, and robotics, thereby enabling scalable, flexible construction workflows.
We want to explore the integration of computational design and robotic fabrication for modular architectural systems. Inspired by projects such as the Kodama Pavilion, this concept allows architectural elements to be designed as individual plates that can be assembled into modules and further combined into larger structures (e.g., columns, beams, or pavilions).
The student will work with an existing computational design pipeline that generates plate geometries, where variations may arise depending on material constraints and design intent. The physical realization involves CNC-milled wooden plates and robotic assembly.
The research question we want to tackle is: given an architectural structure design, how can a robot plan and execute a policy to build it?
The core objective is to develop and implement a robotic assembly process in which a robot autonomously assembles six plates into a single module. While this problem might seem simple, given the robot's kinematic constraints, it involves task and motion planning and becomes very difficult to solve. For planning, we will explore traditional methods, GPU parallelization, and reinforcement learning. If time permits, we will also explore contact-rich policy learning via teleoperation and imitation learning.
Content:
- Understanding and adapting the existing computational design pipeline for plate-based structures
- Development of robotic assembly strategies for modular construction
- Experimental validation through robotic assembly of modules
- Analysis of scalability toward larger architectural structures
Requirements:
- Ongoing master studies in Robotics, Machine Learning, AI
- Interest in robotic fabrication, digital design, or computational architecture
- Background knowledge in Robot Learning
- Experience with Python, JAX, ROS
References:
- Digital Design and Wooden Architecture for Arte Sella Land Art Park
- Reinforcement Learning for Sequential Assembly of SL-Blocks: Self-Interlocking Combinatorial Design Based on Machine Learning
- Learn2assemble with structured representations and search for robotic architectural construction
- Graph-based Reinforcement Learning meets Mixed Integer Programs: An application to 3D robot assembly discovery
Apply to joao.mueller_carvalho@dfki.de with your CV, transcript of records, and a short paragraph on why you are interested in the topic.
Learning Linear State Transitions for Pedestrian Dynamics Using Koopman Operator Theory
Scope: Master's thesis
Advisor: Tomasz Kucner
Added: 2025-11-10
Start: ASAP
Topic:
This thesis investigates the use of Koopman operator theory to model pedestrian dynamics in structured environments such as shopping malls. Using high-frequency trajectory data, the goal is to learn a linear approximation of the environment’s nonlinear dynamics by lifting the state into a higher-dimensional observable space.
The environment is discretized into a spatial grid, with features like pedestrian density and velocity forming a high-dimensional state vector. The challenge is to estimate the full state from partial observations, enabling robots to plan and navigate effectively. The thesis will focus on defining observables, learning the Koopman operator, and validating the model in real-world-inspired scenarios.
Content
- Preprocessing and feature extraction from pedestrian trajectory data
- Definition of observable functions for Koopman lifting
- Learning the Koopman operator from data
- Evaluation of linear approximations for planning and prediction
- Comparison with traditional nonlinear models
Requirements
- Ongoing master studies in Robotics, Applied Mathematics, or related fields
- Strong background in linear algebra, dynamical systems, and machine learning
- Experience with Python and data analysis libraries
- Familiarity with Koopman theory or interest in learning it
- Analytical mindset and interest in human motion modeling
Apply to tomasz.kucner@aalto.fi. Please attach your CV, transcript of records, and a short motivation letter.
Developing a Scalable Multi-Agent Coordination Simulation
Scope: Master's thesis
Advisor: Tomasz Kucner
Added: 2025-11-10
Start: ASAP
Topic:
This thesis focuses on building a scalable simulation platform for coordinating large numbers of agents—robots and humans—moving through shared spaces. The simulator will accept predefined paths and dynamically coordinate agents to avoid collisions and resolve conflicts, ensuring safe and efficient goal achievement.
A key challenge is scalability: the system must maintain real-time performance even with many agents. This will involve designing efficient data structures, leveraging parallelism, and implementing lightweight decision-making rules. The final deliverable is a practical, extensible simulation tool for testing and developing multi-agent coordination strategies.
Content
- Design and implementation of a scalable multi-agent simulation framework
- Development of local avoidance and conflict resolution strategies
- Integration of human and robot motion models
- Optimization for real-time performance using parallel computing
- Evaluation of coordination strategies at scale
Requirements
- Ongoing master studies in Robotics, Computer Science, or related fields
- Strong programming skills in Python or C++
- Experience with simulation frameworks (e.g., ROS, Unity, Webots) is a plus
- Understanding of multi-agent systems and motion planning
- Ability to work independently and solve complex problems
- Interest in large-scale systems and human-robot coexistence
Apply to tomasz.kucner@aalto.fi. Include your CV, transcript of records, and a brief statement of interest.
Multi-Agent State Estimation in Human-Shared Environments Using Partial Macroscopic Observations
Scope: Master's thesis
Advisor: Tomasz Kucner
Added: 2025-11-10
Start: ASAP
Topic:
In environments shared with humans, autonomous agents often operate with limited, localized observations. This thesis investigates how to combine such partial macroscopic observations—like local density, average velocity, or flow direction—into a coherent global state estimate of the environment. The aim is to model the nonlinear, high-dimensional dynamics of such environments using historical data and to develop real-time estimation methods that reconstruct the full state from distributed, incomplete views.
The work will explore advanced filtering techniques such as the Ensemble Kalman Filter and compare them with physics-informed models that incorporate learned operators. These models enable approximate linear representations of the environment’s dynamics, making them suitable for Kalman-based estimation. The final goal is a robust framework for understanding and predicting the global state of dynamic, human-populated environments.
Content
- Modeling nonlinear dynamics of human-shared environments using historical data
- Development of state estimation methods from partial macroscopic observations
- Implementation and evaluation of Ensemble Kalman Filters and physics-informed models
- Comparison of learned vs. predefined dynamic operators
- Real-time reconstruction and prediction of global environment state
Requirements
- Ongoing master studies in Robotics, Computer Science, Control Engineering, or related fields
- Solid understanding of state estimation, filtering techniques, and dynamical systems
- Experience with Python and scientific computing libraries (e.g., NumPy, SciPy, PyTorch)
- Familiarity with multi-agent systems and human-robot interaction is a plus
- Independent and analytical working style
- Interest in real-time systems and human-aware robotics
Apply to tomasz.kucner@aalto.fi. Attach a CV, transcript of records, and a short motivation letter explaining your background and interest in the topic.
Method Development for Reinforcement Learning Race Driver Models in Advanced Motorsport Simulation at Porsche Motorsport
Scope: Master's thesis
Advisor: Siwei Ju
Added: 2025-10-23
Start: ASAP
Topic: 
At Porsche Motorsport, we continuously strive to improve the accuracy, robustness, and efficiency of so-called Digital Twins: digital representations of the system car-racetrack-driver. Within this thesis, you will focus on advancing our race driver model, which is based on reinforcement learning. The goal is to further develop the method and toolchain, targeting improved imitation quality, enhanced generalization, efficiency and performance. In this scope, there will be plenty of scientific challenges to overcome and there will be also opportunities to contribute to scientific publications.
Porsche Motorsport is located in Weissach, and you are expected to work there on site. This position gets a monthly compensation of about 900€.
Content
- Development and implementation of methods to accelerate training of reinforcement learning driver models
- Investigation and application of domain randomization to improve robustness across varying conditions
- Tuning of hyperparameters and training schemes for enhanced model performance
- Evaluation of improvements within the context of lap simulation and setup sensitivity analysis
- Benchmarking against the current state of the art in simulation workflows
Requirements
- Ongoing master studies in Computer Science, Data Science, Engineering, Mechatronics, or related fields
- Solid background in reinforcement learning and machine learning algorithms
- Practical experience with Python and ML frameworks (e.g. TensorFlow, PyTorch)
- Good programming skills in Python or similar
- Knowledge in vehicle dynamics and motorsport applications is an advantage
- Independent, structured, and solution-oriented working style
- Passion for motorsport and technology-driven performance optimization
Apply to siwei.ju@tu-darmstadt.de. Attach a CV, transcript of record and any other documents that support your application, and include a few words about your background and why you are interested in the project.
Model Predictive Control for Ball Juggling
Scope: Master's thesis
Advisor: Kai Ploeger
Added: 2025-08-09
Start: ASAP
Topic:  Toss juggling is one of the most challenging dynamic skills that humans learn to perform through trial and error. While a ball is in the air, the tiniest variations in hand trajectories during the throw can accumulate into large ball state errors at catch time.
In previous projects [2-3], we solved the problem of trajectory planning for juggling to perfection.
In this project, your task is to implement state-of-the-art trajectory tracking controllers, e.g., adaptive Model Predictive Control approaches specialized for cyclic tasks [1]. These controllers can be understood as adaptive learning strategies, continually adjusting to compensate for small deviations, much like humans refine their throws with experience, asymptotically converging to near-zero tracking error. The goal is to juggle as many balls as possible with our real dual-arm high-speed robots.
Toss juggling is one of the most challenging dynamic skills that humans learn to perform through trial and error. While a ball is in the air, the tiniest variations in hand trajectories during the throw can accumulate into large ball state errors at catch time.
In previous projects [2-3], we solved the problem of trajectory planning for juggling to perfection.
In this project, your task is to implement state-of-the-art trajectory tracking controllers, e.g., adaptive Model Predictive Control approaches specialized for cyclic tasks [1]. These controllers can be understood as adaptive learning strategies, continually adjusting to compensate for small deviations, much like humans refine their throws with experience, asymptotically converging to near-zero tracking error. The goal is to juggle as many balls as possible with our real dual-arm high-speed robots.
Requirements
- Strong programming skills, preferably in C++
- Some knowledge of control and optimization
- Prior hands-on experience with robotics and ROS is a plus
Apply to kai.ploeger@tu-darmstadt.de. Attach a CV and include a few words about your background and why you are interested in the project.
References
[1] L. Pabon et al. (2024). Perfecting Periodic Trajectory Tracking: Model Predictive Control with a Periodic Observer (Π-MPC). In IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS).
[2] Ploeger, K., & Peters, J. (2022, October). Controlling the Cascade: Kinematic Planning for n-Ball Toss Juggling. In 2022 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) (pp. 1139–1144). IEEE.
[3] Andreu, M. G., Ploeger, K., & Peters, J. (2024, October). Beyond the Cascade: Juggling Vanilla Siteswap Patterns. In 2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) (pp. 2928–2934). IEEE.
Neural-Symbolic Reasoning for Safe Robot Manipulation
Scope: Master Thesis
Advisor: Puze Liu / Zihan Ye
Added: 2025-03-20
Start: ASAP  Topic: Despite their powerful representational ability, deep neural networks (DNNs) suffer from a fundamental limitation: the “black-box” nature of DNN makes it difficult to guarantee that the outputs are always reasonable and reliable. This lack of transparency raises significant concerns, particularly in safety-critical applications such as robotics, where erroneous predictions or unexpected behaviors can lead to hazardous consequences. The “hallucinations” problem from the generative model severely impedes the adoption of AI in domains that demand high levels of reliability, safety, and interpretability.
Topic: Despite their powerful representational ability, deep neural networks (DNNs) suffer from a fundamental limitation: the “black-box” nature of DNN makes it difficult to guarantee that the outputs are always reasonable and reliable. This lack of transparency raises significant concerns, particularly in safety-critical applications such as robotics, where erroneous predictions or unexpected behaviors can lead to hazardous consequences. The “hallucinations” problem from the generative model severely impedes the adoption of AI in domains that demand high levels of reliability, safety, and interpretability.
In contrast, formal logic-based reasoning provides a structured, transparent, and interpretable framework for decision-making, making it an attractive approach for ensuring safety in AI-driven applications. By integrating deep learning with formal reasoning, a neural-symbolic reasoning framework offers significant advantages: the expressive power and adaptability of neural networks combined with the rigor, interpretable symbolic logic.
In this thesis, we will investigate the neural-symbolic reasoning framework to address safety challenges in robotics. Specifically, we will explore scalable differentiable reasoning techniques to construct safety constraints and develop robust policies that ensure safety for robotic tasks.
Interested students can apply by sending an email to puze.liu@dfki.de.
Requirements
- Strong programming skills in Python
- Basic knowledge of robotics, machine learning, and optimization
- Experience with deep learning libraries (e.g., PyTorch)
- Knowledge on neural symbolic models is a plus
Thesis objectives
- Investigate how to translate symbolic safety specifications into logic-based representation.
- Explore the possibility of training a neural-symbolic reasoner as safety constraints
- Investigate how to integrate the trained safety prediction model into planning, control and RL.
Narrowing the Sim2Real Gap with Differentiable Tactile Simulation
Scope: Bachelor/Master's thesis
Advisor: Guillaume Duret
Added: 2025-01-13
Start: ASAP
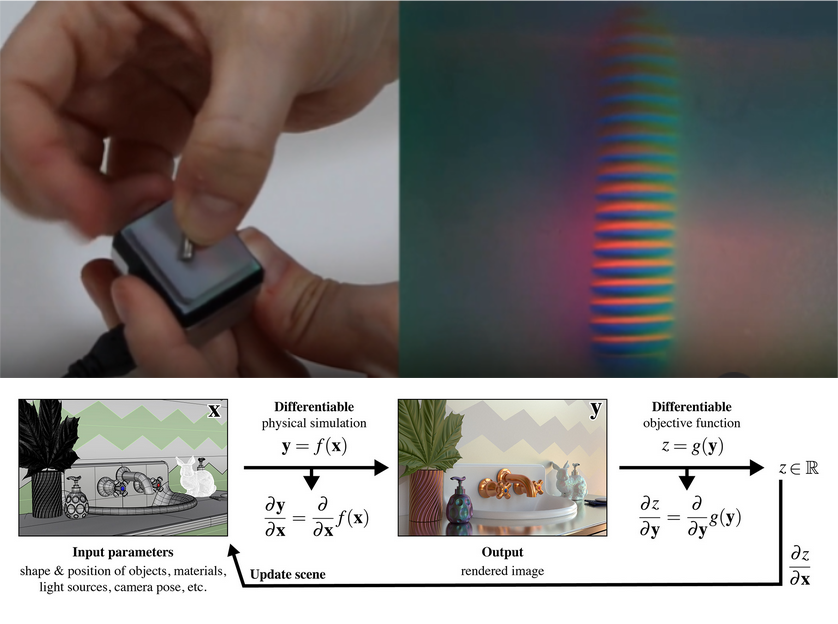
Topic: Sim2Real (simulation-to-real transfer) is critical in robotic learning due to the high demand for data required to train effective models. Simulations provide a controlled and cost-effective means to generate data, reducing the risks and challenges associated with training in real-world environments. However, the inherent discrepancy between simulated and real-world conditions, known as the _sim2real gap_, presents a significant challenge. Minimizing this gap is essential to ensure the transferability of models from simulation to real-world applications. This thesis will investigate methods to refine and adapt simulations to closely replicate the specific characteristics of real tactile sensors, such as the GelSight Mini. The research will focus on leveraging advanced simulation techniques, including differentiable rendering, to optimize simulator parameters automatically. These properties may include camera distortion, sensor positioning, lighting conditions, and color rendering, ensuring high fidelity with the real sensor. By systematically exploring and comparing approaches for fine-tuning simulation environments, this work aims to enhance the accuracy of simulated data and improve the robustness of robotic learning models in real-world settings. The findings will contribute to reducing the sim2real gap and advancing the applicability of tactile sensing in robotics.
Interested students can apply by sending an email to guillaume.duret@ec-lyon.fr, attaching the following documents:
- Curriculum Vitae (CV)
- A motivation letter explaining the reasons for applying to this thesis and outlining academic and career objectives
Requirements
- Strong programming skills in Python
- Basic knowledge of robotics, machine learning, and optimization
- Experience with deep learning libraries (e.g., PyTorch)
- Experience with rendering and computer graphics is a plus
Thesis objectives
- Use differentiable rendering libraries [1] in the context of visual-tactile sensors such as the GelSight mini and demonstrate their ability to produce realistic rendering simulated properties.
- Compare the methods in terms of ease of use and quality with the existing state-of-the-art methods [2] in different contexts.
- Demonstrate the effectiveness of the developed method in a robotic manipulation task
References
[1] https://mitsuba.readthedocs.io/en/stable/src/inverse_rendering/pytorch_mitsuba_interoperability.html
[2] Si, Z., & Yuan, W. (2021). Taxim: An Example-based Simulation Model for GelSight Tactile Sensors. _IEEE Robotics and Automation Letters, PP_, 1-1.