
NIPS 2014 Workshop: Autonomously Learning Robots
Quick Facts
| Organizers: | Gerhard Neumann (TU-Darmstadt), Joelle Pineau (McGill University), Peter Auer (Uni Leoben), Marc Toussaint (Uni Stuttgart) |
| Conference: | NIPS 2014 |
| Location: | Montreal, Convention Center, Level 5; Room 512 d, h |
| Date: | December, 12th, 2014 |
Schedule
- 8:30-8:45: Opening Remarks
- 8:45-9:15: Invited Talk: Drew Bagnell, The Space Between: Anytime Prediction and Computation-Aware Machine Learning
- 9:15-9:30: Short Talk:Resilient Robots thanks to Bayesian Optimization and Intelligent Trial and Error: Evolutionary Computation, J.P. Mouret
- 9:30-10:00: Ashutosh Saxena, Robo Brain: Large-Scale Knowledge Engine for Robots
- 10:00-10:30: Coffee Break / Posters Session 1
- 10:30-11:00: Posters Session 1
- 11:00-11:30: Invited Talk: Daniel Polani, Informational Routes towards Exploration and Capture of Agent Spaces
- 11:30-11:45: Layered Inverse Optimal Control for Learning From Demonstrations, Arunkumar Byravan
- 11:45-12:00: Short Talk: Functional Gradient Motion Planning in Reproducing Kernel Hilbert Spaces, Zita Marinho
Lunch / Posters
- 3:00-3:30: Invited Talk: George Konidaris, Robots, Skills, and Symbols
- 3:30-4:00: Invited Talk: Lesli Pack Kaelbing, Deciding What to Learn
- 4:00-4:30: Poster Session 2
- 4:30-5:00: Coffee Break / Poster Session 2
- 5:00-5:30: Invited Talk: Martin Riedmiller, Learning Machines - 4 Relevant Research Dimensions
- 5:30-5:45: Short Talk: Inverse KKT Motion Optimization, Peter Englert
- 5:45-6:00: Short Talk: Embedded Transition Distributions for High-Dimensional Policy Search, Herke von Hoof
- 6:00-6:30: Closing Remarks and Discussion
Topics
- More Autonomous Reinforcement Learning for Robotics
- Autonomous Sub-Goal Extraction
- Bayesian Parameter and Model Selection
- Active Search and Autonomous Exploration
- Autonomous Feature Extraction, Kernel Methods and Deep Learning for Robotics
- Learning from Human Instructions, Inverse Reinforcement Learning and Preference Learning for Robotics
- Generalization of Skills with Multi-Task Learning
- Learning Forward Models and Efficient Model-Based Policy Search
- Learning to Exploit the Structure of Control Tasks
- Movement Primitives and Modular Control Architectures
Invited Speakers
Drew Bagnell, Carnegie Mellon (CMU)
Title: The Space Between: Anytime Prediction and Computation-Aware Machine Learning
Learning in robotics appears easy: find the latest and greatest algorithm at NIPS and apply it to a new platform or domain. It rarely turns out that way. Instead, we find in the literature and in practice complex staged predictors, cascades of decisions, arbitrary cut-offs, and uncontrolled approximations--- all to support the needs of a larger system that can’t wait for a learning algorithm to answer. Simplicity and statistical performance are sacrificed to make predictions in a reasonable time.
More “autonomous” learning is an illusion unless we confront the tremendous engineering effort currently needed to realize computationally effective learning systems. I’ll present a new approach— Anytime Prediction-- to supervised learning that ensures prediction on-demand. The resulting algorithms are simple to implement and provide rigorous guarantees and practical performance. I’ll describe extensions to dynamically adapt computational effort and speculate on the future of computation-aware machine learning.
Bio: J. A. (Drew) Bagnell is an Associate Professor at Carnegie Mellon University’s Robotics Institute, National Robotics Engineering Center (NREC) and the Machine Learning Department. His research focuses on machine learning for automated decision-making, two- and three-D computer vision, adaptive control, optimization and planning under uncertainty. His contributions include elements of the theory and practice of imitation learning, the first reinforcement learning algorithm for helicopter control, developing inverse optimal control methods for imitation learning in both field and legged robotics, and developing machine learning techniques for automated 2D/3D perception and control on programs ranging from commercial driver assistance to autonomous mining. His interests in artificial intelligence range from algorithmic and basic theoretical development to delivering fielded learning-based systems.
Daniel Polani, University of Hertfordshire
Title: Informational Routes towards Exploration and Capture of Agent Spaces
Shannon's theory of information has set in motion one of the most farcical trains of misconceptions and misunderstandings in the modern history of the sciences, namely, that 'information' is a palpable thing with sufficient integrity to be measured and parceled out like so many dollops of butterscotch. (Philip Mirowski, 2002)
Shannon information has been used successfully for exploration in various ways, most typically by utilizing concepts such as "information gain" to characterize the most profitable follow-up action, depending on the exploring agent's state of knowledge.
However, there are alternative routes towards this end. For instance, one can consider information as a quantity to be injected by the agent into the environment or parceled into "useful and useless" by the agent.
This philosophy gives rise to quantities such as "empowerment" or "relevant information". The first one forms the channel capacity of the agent's perception-action loop; in a way, it measures the agent's informational impedance match with its niche. The second one allows to parcel out the "information" that an agent needs to take in from its environment. The talk will introduce these principles and illustrate with selected examples how they can help agents capturing the structure of their space.
Leslie Pack Kaelbing, Massachusetts Institute of Technology (MIT)
Titlle: Deciding What to Learn
Basic technology in robotics and in machine learning has made great improvements in recent years. How can we most effectively integrate the two? There are many learning problem formulations (supervised, policy learning, value-function learning, model learning), many representational choices (fixed feature vectors, relational descriptions, conditional probability distributions, rule sets), and many subproblems to which they can be applied (perception, motor control, state estimation, high-level action selection). I'll outline one choice of an integrated architecture (going from primitive perception through high-level action selection and back to low-level control) and discuss a number of learning problems that can be formulated in that context.
Ashutosh Saxena, Cornell University
Title: Robo Brain: Large-Scale Knowledge Engine for Robots
In this talk, I'll present a knowledge engine, which learns and shares knowledge representations, for robots to carry out a variety of tasks. Building such an engine brings with it the challenge of dealing with multiple data modalities including symbols, natural language, haptic senses, robot trajectories, visual features and many others. The knowledge stored in the engine comes from multiple sources including physical interactions that robots have while performing tasks (perception, planning and control), knowledge bases from WWW and learned representations from leading robotics research groups.
We discuss various technical aspects and associated challenges such as modeling the correctness of knowledge, inferring latent information and formulating different robotic tasks as queries to the knowledge engine. We describe the system architecture and how it supports different mechanisms for users and robots to interact with the engine. Finally, we demonstrate its use in three important research areas: grounding natural language, perception, and planning, which are the key building blocks for many robotic tasks. This knowledge engine is a collaborative effort and we call it RoboBrain.
George Konidaris, Duke University
Title: Robots, Skills, and Symbols
Robots are increasingly becoming a part of our daily lives, from the automated vacuum cleaners in our homes to the rovers exploring Mars. However, while recent years have seen dramatic progress in the development of affordable, general-purpose robot hardware, the capabilities of that hardware far exceed our ability to write software to adequately control.
The key challenge here is one of abstraction. Generally capable behavior requires high-level reasoning and planning, but perception and actuation must ultimately be performed using noisy, high-bandwidth, low-level sensors and effectors. I will describe recent research that uses hierarchical reinforcement learning as a basis for constructing robot control hierarchies through the use of learned motor controllers, or skills.
The first part of my talk will address autonomous robot skill acquisition. I will demonstrate a robot system that learns to complete a task, and then extracts components of its solution as reusable skills, which it deploys to quickly solve a second task. The second part will briefly focus on practical methods for acquiring skill control policies, through the use human demonstration and active learning. Finally, I will present new results establishing a link between the skills available to a robot and the abstract representations it should use to plan with them. I will discuss the implications of these results for building true action hierarchies for reinforcement learning problems.
Bio: George Konidaris is an Assistant Professor of Computer Science and Electrical and Computer Engineering at Duke University. He holds a BScHons from the University of the Witwatersrand, an MSc from the University of Edinburgh, and a PhD from the University of Massachusetts Amherst, having completed his thesis under the supervision of Professor Andy Barto. Prior to joining Duke, he was a postdoctoral researcher at MIT with Professors Leslie Kaelbling and Tomas Lozano-Perez.
Martin Riedmiller, University of Freiburg
Title: Learning Machines - 4 Relevant Research Dimensions
Methods for reinforcement learning in real world settings have made a lot of progress in recent years. In this talk, I will discuss 4 research directions, that are relevant for building truly universal learning controllers. Our aim is a general learning control architecture, that is immediately applicable in a wide range of real world scenarios. I will give 4 real-world examples of learning machines showing our efforts towards this goal.
Bio: Martin Riedmiller studied Computer Science at the University of Karlsruhe, Germany, where he received his diploma in 1992 and his PhD in 1996. In 2002 he became a professor for Computational Intelligence at the University of Dortmund, from 2003 to 2009 he was heading the Neuroinformatics Group at the University of Osnabrueck. Since April 2009 he is a professor for Machine Learning at the Albert-Ludwigs-University Freiburg. He was participating with his teams in the RoboCup competitions from 1998 to 2009, winning 5 world championship titles and several European championships. In 2010, he founded Cognit labs GmbH, a startup focussing on self learning machines. In 2013, he was a visiting researcher at DeepMind (now Google DeepMind) during a sabbatical year.
His research interests are machine learning, neural networks, reinforcement learning and robotics.
Paper submissions
We accepted 21 papers for the workshop. Due to the large number of posters, there will be 2 poster sessions.
Poster session 1 (10:00 - 11:00):
- Bellmanian Bandit Network, A. Bureau, M. Sebag: PDF
- Data-Efficient Inverse Reinforcement Learning under Unknown Dynamics, A. Byravan, D. Fox, M. Deisenroth: PDF
- Learning on the Job: Improving Robot Perception Through Experience, C. Gurau, J. Hawke, C. Tong, I. Posner, PDF
- Resilient Robots thanks to Bayesian Optimization and Intelligent Trial and Error, A. Cully, J. Clune, J.P. Mouret, Link to x-Archive
- GPU based Path Integral Control with Learned Dynamics, G. Williams, E. Rombokas, T. Daniel, PDF
- Building a Curious Robot for Mapping, L. Lehnert, D. Precup, PDF
- Functional Gradient Motion Planning in Reproducing Kernel Hilbert Spaces, Z, Marinho, A, Dragan, A. Byravan, Srinivasa S., Gordon G. Boots B., PDF
- Collaborative goal and policy learning from human operators of construction co-robots, H. Maske, M. Matthews, A. Axelrod, H. Mohammadipanah, G. Chowdhary, C. Crick, P. Pagilla, PDF
- Direct Value Learning: a Rank-Invariant Approach to Reinforcement Learning, B. Mayeur, R. Akrour, M. Sebag, PDF
- Model-based Path Integral Stochastic Control: A Bayesian Nonparametric Approach, Y. Pan, E. Theodorou, M. Kontitsis, PDF (unfortunately will not be presented due to VISA issues)
Poster session 2 (16:00 - 17:00):
- Learning to Predict Events On-line: A Semi-Markov Model for Reinforcement Learning, F. Rivest, R. Kohar, N. Boukary, PDF
- Spatial Bags of Visual Words, J. Straub, N. Bhandari, J. Fisher, PDF
- Data as Demonstrator with Applications to System Identification, A. Venkatraman, B. Boots, M. Hebert, J. Bagnell, PDF
- Embedded Transition Distributions for High-Dimensional Policy Search, H. van Hoof, J. Peters, G.Neumann
- Incremental Sparse GP Regression for Continuous-time Trajectory Estimation & Mapping, X. Yan, V. Indelman, B. Boots, PDF
- Robot Learning Manipulation Action Plans by “Watching” Unconstrained Videos, Y. Yang, C. Fernmüller, Y. Aloimonos, Y. Li, PDF
- Layered Hybrid Inverse Optimal Control for Learning Robot Manipulation from Demonstration, A. Byravan, M. Montfort, B. Ziebart, B. Boots, D. Fox
- Inverse KKT Motion Optimization: A Newton Method to Efficiently Extract Task Spaces and Cost Parameters from Demonstrations, P. Englert, M. Toussaint: PDF
- Learning Task-Specific Path-Quality Cost Functions From Expert Preference, A. Gritsenko, D. Berenson (unfortunartely will not be presented because of visa issues), PDF
- Learning Transition Dynamics in MDPs with Online Regression and Greedy Feature Selection, G. Lever, R. Stafford , J. Shawe-Taylor, PDF
- Message Propagation based Place Recognition with Novelty Detection, L. Ott, F. Ramos, PDF
Abstract:
To autonomously assist human beings, future robots have to autonomously learn a rich set of complex behaviors. So far, the role of machine learning in robotics has been limited to solve pre-specified sub-problems that occur in robotics and, in many cases, off-the-shelf machine learning methods. The approached problems are mostly homogeneous, e.g., learning a single type of movement is sufficient to solve the task, and do not reflect the complexities that are involved in solving real-world tasks.

In a real-world environment, learning is much more challenging than solving such homogeneous problems. The agent has to autonomously explore its environment and discover versatile behaviours that can be used to solve a multitude of different tasks throughout the future learning progress. It needs to determine when to reuse already known skills by adapting, sequencing or combining the learned behaviour and when to learn new behaviours. To do so, it needs to autonomously decompose complex real-world tasks into simpler sub-tasks such that the learned solutions for these sub-tasks can be re-used in a new situation. It needs to form internal representations of its environment, which is possibly containing a large variety of different objects or also different agents, such as other robots or humans. Such internal representations also need to shape the structure of the used policy and/or the used value function of the algorithm, which need to be flexible enough such to capture the huge variability of tasks that can be encountered in the real world. Due to the multitude of possible tasks, it also cannot rely on a manually tuned reward function for each task, and, hence, it needs to find a more general representations for the reward function. Yet, an autonomous robot is likely to interact with one or more human operators that are typically experts in a certain task, but not necessarily experts in robotics. Hence, an autonomously learning robot also should make effective use of feedback that can be acquired from a human operator. Typically, different types of instructions from the human are available, such as demonstrations and evaluative feedback in form of a continuous quality rating, a ranking between solutions or a set of preferences. In order to facilitate the learning problem, such additional human instructions should be used autonomously whenever available. Yet, the robot also needs to be able to reason about its competence to solve a task. If the robot thinks it has poor competence or the uncertainty of the competence is high, the robot should request more instructions from the human expert.

Most machine learning algorithms are missing these types of autonomy. They still rely on a large amount of engineering and fine-tuning from a human expert. The human typically needs to specify the representation of the reward-function, of the state, of the policy or of other internal representations used by the learning algorithms. Typically, the decomposition of complex tasks into sub-tasks is performed by the human expert and the parameters of such algorithms are fine tuned by hand. The algorithms typically learn from a pre-specified source of feedback and can not autonomously request more instructions such as demonstrations, evaluative feedback or corrective actions. We belief that this lack of autonomy is one of the key reasons why robot learning could not be scaled to more complex, real world tasks. Learning such tasks would require a huge amount of fine tuning which is very costly on real robot systems.
Goal:
In this workshop, we want to bring together people from the fields of robotics, reinforcement learning, active learning, representation learning and motor control. The goal in this multi-disciplinary workshop is to develop new ideas to increase the autonomy of current robot learning algorithms and to make their usage more practical for real world applications. In this context, among the questions which we intend to tackle are
More Autonomous Reinforcement Learning
- How can we automatically tune hyper-parameters of reinforcement learning algorithms such as learning and exploration rates?
- Can we find reinforcement learning algorithms that are less sensitive to the settings of their hyper-parameters and therefore, can be used for a multitude of tasks with the same parameter values?
- How can we efficiently generalize learned skills to new situations?
- Can we transfer the success of deep learning methods to robot learning?
- How do learn on several levels of abstractions and also identify useful abstractions?
- How can we identify useful elemental behaviours that can be used for a multitude of tasks?
- How do use RL on the raw sensory input without a hand-coded representation of the state?
- Can we learn forward models of the robot and its environment from high dimensional sensory data? How can these forward models be used effectively for model-based reinforcement learning?
- Can we autonomously decide when to learn value functions and when to use direct policy search?
Autonomous Exploration and Active Learning
- How can we autonomously explore the state space of the robot without the risk of breaking the robot?
- Can we use strategies for intrinsic motivation, such as artificial curiosity or empowerment, to autonomously acquire a rich set of behaviours that can be re-used in the future learning progress?
- How can we measure the competence of the agent as well as our certainty in this competence?
- Can we use active learning to acquire improve the quality of learned forward models as well as to probe the environment to gain more information about the state of the environment?
Autonomous Learning from Instructions
- Can we combine learning from demonstrations, inverse reinforcement learning and preference learning to make more effective use of human instructions?
- How can we decide when to request new instructions from a human experts?
- How can we scale inverse reinforcement learning and preference learning to high dimensional continuous spaces?
- Can we use demonstrations and human preferences to identify relevant features from the high dimensional sensory input of the robot?
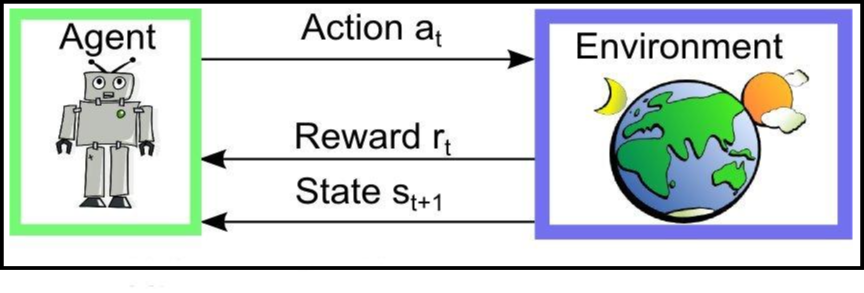
Autonomous Feature Extraction
- Can we use feature extraction techniques such as deep learning to find a general purpose feature representation that can be used for a multitude of tasks.
- Can recent advances for kernel based methods be scaled to reinforcement learning and policy search in high dimensional spaces?
- What are good priors to simplify the feature extraction problem?
- What are good features to represent the policy, the value function or the reward function? Can we find algorithms that extract features specialized for these representations?
Format:
The workshop is designed to be a platform for presentations and discussion including the invited speakers, oral presentations of paper submissions and poster submissions. The scope of the workshop includes all all areas connected to autonomous robot learning, including reinforcement learning, exploration strategies, Bayesian learning for adjusting hyper-parameters, representation learning, structure learning and learning from human instructions. There will be a poster session where interested authors in the topic can present their recent work at the workshop. The authors have to submit a two to six pages paper which can present new work, or a summary of the recent work of the authors or also present new ideas for the proposed topics. The workshop will consist of 6 plenary invited talks (30 minutes each) and short talks from selected abstract submissions. All accepted posters will be presented at two poster sessions (min. 60 minutes each).
Call for Papers
Authors can submit a 2-6 pages paper that will be reviewed by the organization committee. The papers can present new work or give a summary of recent work of the author(s). All papers will be considered for the poster sessions. Out-standing long papers (4-6 pages) will also be considered for a 20 minutes oral presentation. Submissions should be send per email to autonomous.learning.robots@gmail.com with the prefix [ALR-Submission]. Please use the standard NIPS style-file for the submissions. Your submission should be anonymous, so please do not add the author names to the PDF.
Travel Scholarship for Students
We are offering a travel scholarship for students that want to attend the workshop. The scholarship will be at maximum 500€ (approx. 630$) per student and will be handed out to the best 10 student submissions. Please indicate in the email of your submission whether the first author is a student and you want to apply for the scholarship.
Important Dates
- 1st Call for Papers: August, 26th, 2014
- Extended Paper submission deadline: October, 10th, 2014 (23:59 PST)
- Paper acceptance notification: October, 27th, 2014
- Camera-ready deadline: November, 30th, 2014
Acknowledgements
This workshop is in held in close collaboration with the EU-Project Complacs.  We also thank the DFG Priority Programme 1527 "Autonomous Learning" for the support and the provision of the travel scholar ships.
We also thank the DFG Priority Programme 1527 "Autonomous Learning" for the support and the provision of the travel scholar ships.