
I am now in Sony AI, Japan. My up-to-date webpage is here.
Guilherme J. Maeda
Research Interests
Robotics; Human-Robot Collaboration, Learning and Adaptive Control; Movement Representation and Generation
More Information
Publications Google Citations DBLP Curriculum Lattes (for Brazilian researchers)
Code
Interaction ProMPs Local time warping
Contact Information
 Guilherme is a research scientist at the Intelligent Autonomous Systems group (IAS) in TU Darmstadt since November 2013. He is the IAS team leader for the 3rdHandRobot Project (below you will find some recent videos related to the project).
Guilherme is a research scientist at the Intelligent Autonomous Systems group (IAS) in TU Darmstadt since November 2013. He is the IAS team leader for the 3rdHandRobot Project (below you will find some recent videos related to the project). His goal is to enable robots to learn challenging tasks by interacting with humans and with the environment. To this end, his research bridges the areas of control, learning, and human-robot collaboration.
Guilherme received his PhD from the Australian Centre for Field Robotics (ACFR). He did his work under the supervision of Hugh Durrant-Whyte, Surya Singh, David Rye, and Ian Manchester. Motivated by the mining industry, his work investigated the combined use of data-driven iterative learning methods and state estimation applied to autonomous excavators. His thesis is available here.
Between 2005-2007 he did his masters at the Tokyo Institute of Technology (TITECH) in the field of precision positioning control. Guilherme also worked from 2007 to 2009 at IHI Corporation researching novel mechanical designs and control methods for heavy industrial equipment such as industrial end-effectors and large-scale roller printers.
Key References
-
- Maeda, G.; Neumann, G.; Ewerton, M.; Lioutikov, R.; Kroemer, O.; Peters, J. (2017). Probabilistic Movement Primitives for Coordination of Multiple Human-Robot Collaborative Tasks, Autonomous Robots (AURO), 41, 3, pp.593-612.
-
- Maeda, G.; Ewerton, M.; Koert, D; Peters, J. (2016). Acquiring and Generalizing the Embodiment Mapping from Human Observations to Robot Skills, IEEE Robotics and Automation Letters (RA-L), 1, 2, pp.784--791.
-
- Maeda, G.; Ewerton, M.; Neumann, G.; Lioutikov, R.; Peters, J. (2017). Phase Estimation for Fast Action Recognition and Trajectory Generation in Human-Robot Collaboration, International Journal of Robotics Research (IJRR), 36, 13-14, pp.1579-1594.
Complete list of publications: Publication Page
News & current activities
- Our paper "Active Incremental Learning of Robot Movement Primitives" has been accepted at the 1st Annual Conference on Robot Learning (CoRL 2017).
- I am giving two talks at the IROS 2017 workshops.
Human in-the-loop robotic manipulation: on the influence of the human role on the 24th of September, and Shared Autonomy. Joint Learning in Human-Robot Collaboration. on the 28th.
- New paper accepted at IROS 2017:
- Busch, B.; Maeda, G.; Mollard, Y.; Demangeat, M.; Lopes, M. (2017). Postural Optimization for an Ergonomic Human-Robot Interaction, Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS).
Past news
- I will be serving as associate editor for IROS 2017
- Invited talk at PUC-Chile
- Invited speaker at the ERF 2017 Workshop: Teaching by Demonstration for Industrial Applications (March 22, Edinburgh)
- Visiting and giving a talk at the Queensland University of Technology (QUT) in February
- Visiting and giving a talk the Advanced Telecommunications Research Institute International (ATR) in February
- IROS 2016. Towards Co-Adaptive Learning Through Semi-Autonomy and Shared Control
Research
Active Incremental Learning of Robot Movement Primitives
(:youtube s9kG_IKzqO4:)
Robots that can be programmed by non-technical users must be capable of learning new tasks incrementally, via demonstrations. This poses the problem of selecting when to teach a new robot skill, or when to generalize a skill based on the current robot's repertoire. Ideally, robots should actively make such decisions, rather than the human. If a robot can quantify the suitability of its own skill set for a given query, it can decide whether it is confident enough to execute the task by itself, or if it should request a human for demonstration.
We are currently investigating algorithms for active requests for incremental learning of reaching skills via human demonstrations. Gaussian processes are used to extrapolate the current skill set with confidence margins, which are then encoded as movement primitives to accurately reach the desired query in the workspace of the robot. This combination allows the robot to generalize its primitives using as few as a single demonstration. In the video you can see a robot indicating to the user which demonstrations should be provided to increase its repertoire of skills. The experiment also shows that the robot becomes confident in reaching objects for whose demonstrations were never provided, by incrementally learning from the neighboring demonstrations.
Optimizing the Mapping from Human Observations to Robot Kinematics
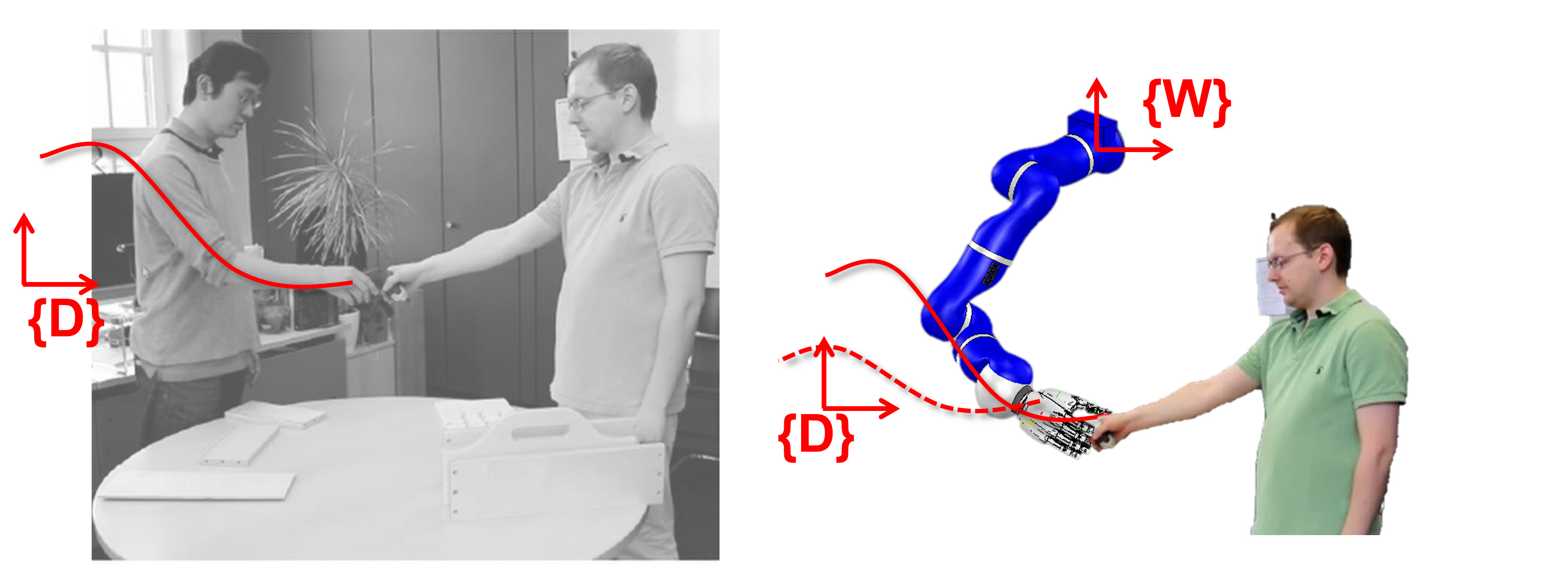
Imitation learning is useful to endow robots with skills that are difficult, if not impossible, to program by hand. For example, a golf swing movement that exploits the redundancy of a 7 degree-of-freedom arm, or a collaborative skill that must be coordinated with the movement of a human partner. Kinesthetic teaching and teleoperation are now widely accepted methods to provide demonstrations for imitation learning, mainly because they avoid the correspondence problem. However, these methods are still far from ideal. In human-robot collaboration, kinesthetic teaching is disruptive and natural interactions cannot be demonstrated. When learning skills, the physical embodiment of the robot obstructs truly optimal and natural human demonstrations.
(:youtube 0d8qwrGHPR8:) Ideally, robots should learn simply by observing the human. Direct observations pose the problem that a movement that can be demonstrated well by a human may not be kinematically feasible for robot reproduction. In this paper we address this problem by using stochastic search to both find the appropriate location of the demonstration reference frame w.r.t the robot, and to adapt the demonstrated trajectory, simultaneously. This means that a human demonstrator can show the skill anywhere without worrying if the robot is capable or not of reproducing it kinematically. Our optimizer aims at finding a feasible mapping for the robot such that its movement resembles the original human demonstration.
-
- Maeda, G.; Ewerton, M.; Koert, D; Peters, J. (2016). Acquiring and Generalizing the Embodiment Mapping from Human Observations to Robot Skills, IEEE Robotics and Automation Letters (RA-L), 1, 2, pp.784--791.
Phase Estimation of Human Movements for Responsive Human-Robot Collaboration
(:youtube bUVn0AwAb1U:)
While probabilistic models are useful to classify and infer trajectories, a common problem is that their construction usually requires the time alignment of training data such that spatial correlations can be properly captured. In a single-agent robot case this is usually not a problem as robots move in a controlled manner. However, when the human is the agent that provides observations, repeatability, and temporal consistency becomes an issue as it is not trivial to align partially observed trajectories of the observed human with the probabilistic model, particularly online and under occlusions. Since the goal of the human movement is unknown, it is difficult to estimate the progress or phase of the movement. We approach this problem by testing many sampled hypotheses of his/her movement speed online. This usually allows us to recognize the human action and generate the appropriate robot trajectory. The video shows some of the benefits of estimating phases for faster robot reactions. It also shows the interesting case when the robot tries to predict the human motion too early, therefore leading to some awkward/erroneous coordination. Details can be found in this paper.
Learning Multiple Tasks with Interaction Probabilistic Movement Primitives from Unlabeled Data
Gaussians allow us to compute things easily. The use of Gaussians to represent Interaction ProMPs means that human-robot movements correlate linearly. Empirically we tested that this assumption actually holds locally, but they do not allow us to create a single interaction model that has global coverage of the state-space. Moreover, as a single Interaction ProMP only represents one task, multiple tasks require multiple Interaction ProMPs trained independently. Here we propose a mixture of interaction primitives where tasks are learned from unlabeled data, in an unsupervised fashion. Referring to the figure below, during the training, the algorithm receives unlabeled weights of several demonstrations and improves the estimates of the parameters that describe multiple human-robot collaborative tasks. During inference, the method generates a posterior distribution of trajectories conditioned on the most probable mixture component with respect to the current observation of the human.
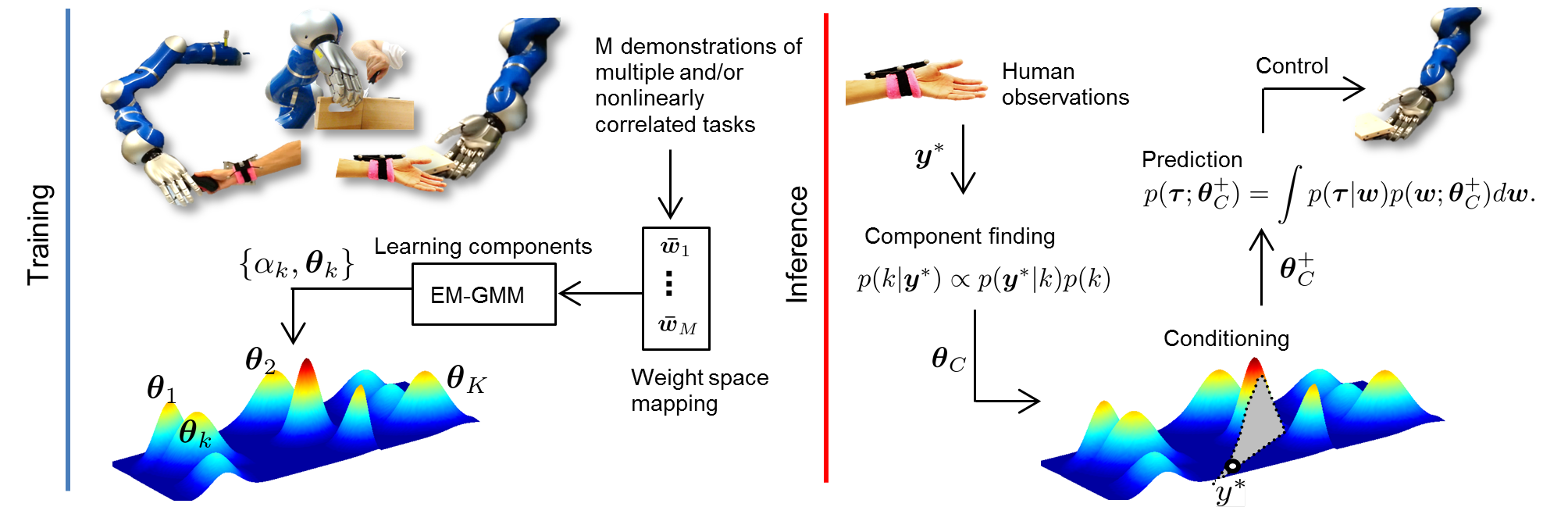
Details of the work can be found here.
This video shows a robot coworker helping a human assembling a toolbox. Differently from our previous video, here the tasks are learned from unlabeled data, in an unsupervised fashion. We introduce the use of a mixture of Interaction Probabilistic Movement Primitives.
Interaction Probabilistic Movement Primitives
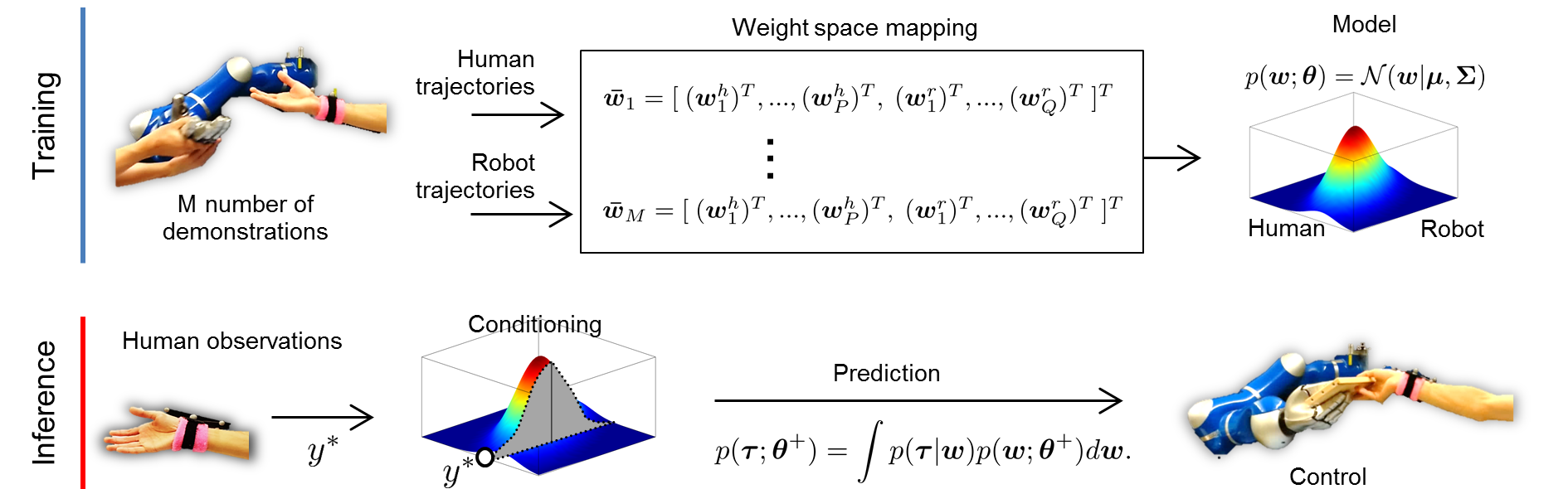
Interaction Probabilistic Movement Primitive (Interaction ProMP) is a probabilistic framework based on Movement Primitives that allows for both human action recognition and for the generation of collaborative robot policies. The parameters that describe the interaction between human-robot movements are learned via imitation learning. The procedure results in a probabilistic model from which the collaborative robot movement is obtained by (1) conditioning at the current observation of the human, and (2) inferring the corresponding robot trajectory and its uncertainty.
The illustration below summarizes the workflow of Interaction ProMP where the distribution of human-robot parameterized trajectories is abstracted to a single bivariate Gaussian. The conditioning step is shown as the slicing of the distribution a the observation of the human. In the real case, the distribution is multivariate and correlates all the weights of all demonstrations.
You can read the paper here. and get the code here.
(:youtube 2Ok6KQQQDNQ:)
Interactive Reaching Task and Toolbox Assembly.
This video shows how kinesthetic teach-in is used to obtain pairs of human-robot trajectories, which are then used as training data for the realization of Interaction Probabilistic Movement Primitives. It also shows a practical application of the method where the robot is used as a coworker to help a human assembling a toolbox. In this case the different collaborative tasks have been previously hand-labeled and the interaction primitives were learned independent from each other.
(:youtube 5c1VP7BLMFs:)
A Personal Assistive Robot
This video shows our robot being used as a caregiver assistive robot. The algorithm is based on Interaction Probabilistic Movement Primitives. Details of the algorithm can be found in this work.
Code
Interaction ProMP
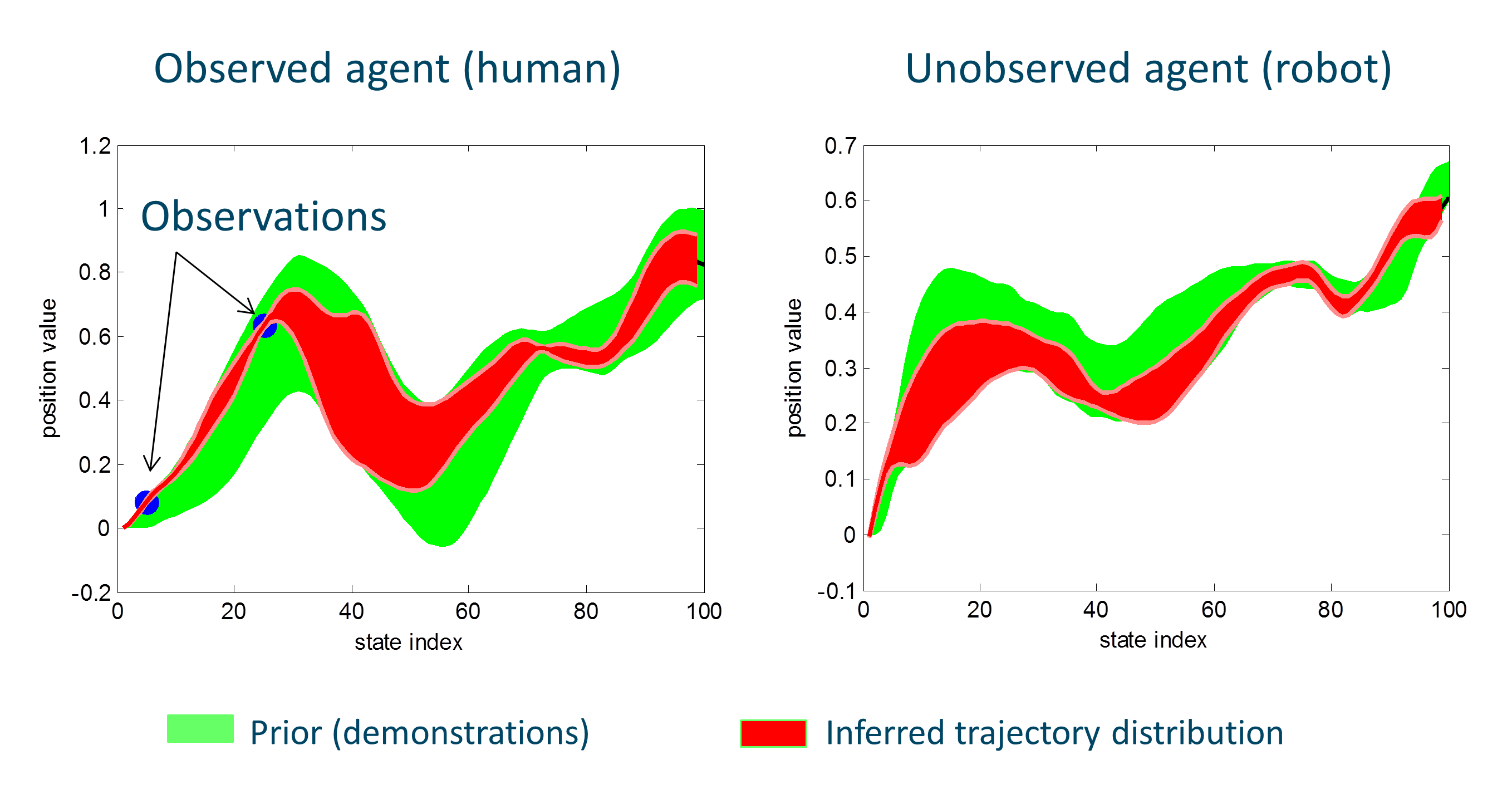
This code in Matlab shows a simple toy problem example where an observed agent with two degrees-of-freedom (DoF) is trained together with an unobserved agent, also with two DoFs. The observed agent could be the human, and the unobserved agent the robot. Note that to collect training data we assume both agents are observed. This means that we will learn the initial distribution by demonstrations. Once the model is learned (the green patch in the figure), we can observe only the human (the two blue dots) to find out a posterior distribution (the red patch), which can be used to control a robot. The code can be found here here, and the original paper is here.
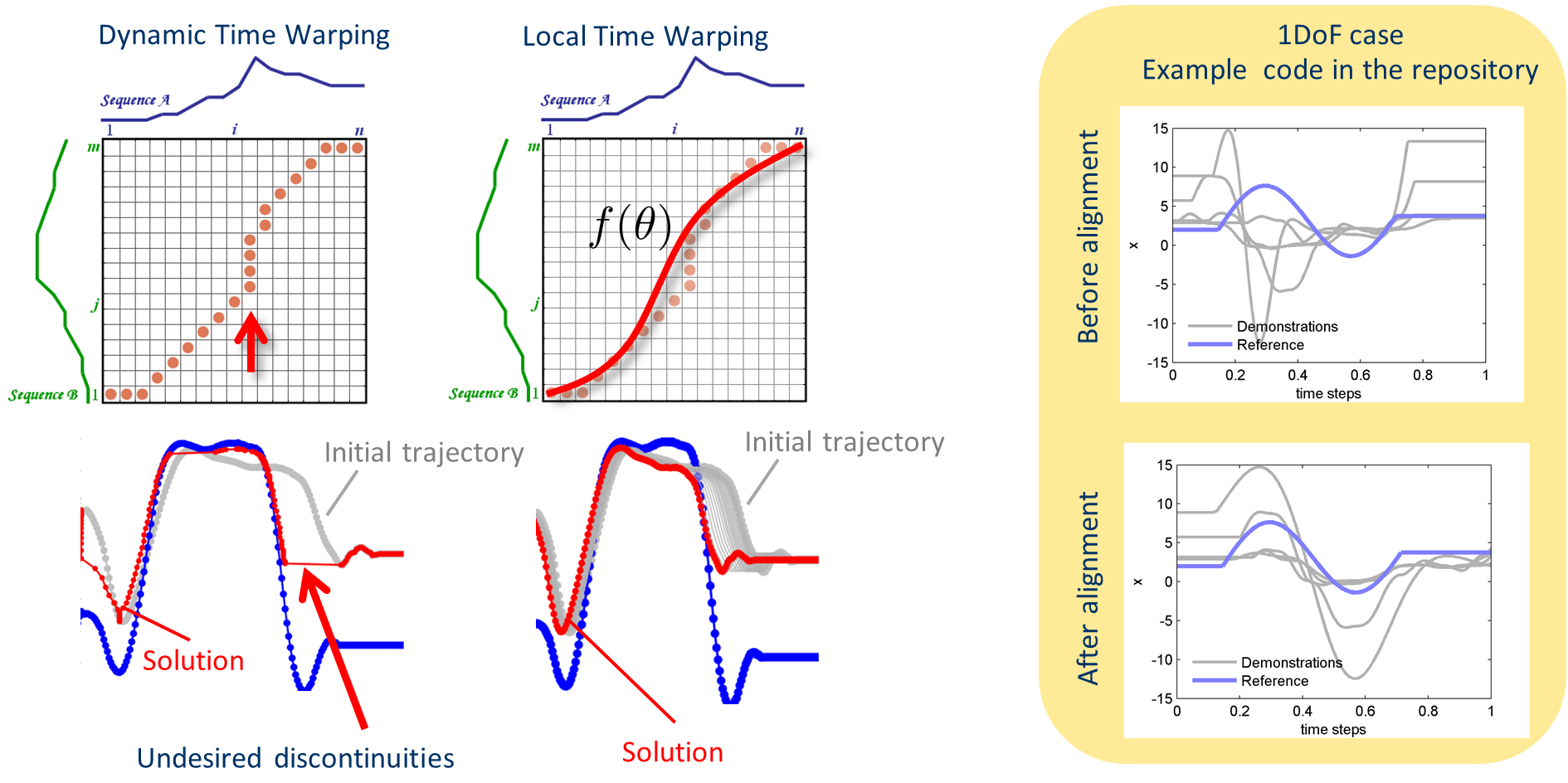
Local Time Warping
Aligning the phase of the motion of different trajectories to a single reference phase is usually a recurrent problem. This is particularly an issue of probabilistic models that are constructed from multiple demonstrations. Often Dynamic Time Warping (DTW) is used. It provides a global optimal solution and works pretty well when trajectories are somewhat similar. When trajectories are extremely different DTW tends to generate unnatural solutions, usually caused by having many time indexes of one trajectory being repeated at the other trajectory. Heuristics to avoid this problem were already addressed in the seminal paper of Sakoe and Chiba 1978. This problem is critical for trajectories of dynamical systems and one alternative is to enforce a 1:1 mapping on time indexes. This can be achieved by imposing a smooth function on the time alignment mapping using local optimization. The code in the repo provides this idea implemented in Matlab. There is no free lunch, we trade-off the heuristics of DTW by the usual heuristics of a local optimizer (initial guess, learning rate, convergence criteria). But in my experience, the usual parameters of an optimizer are much easier to adjust and cover a larger range of data input. Try it yourself: source code with a short explanation of the method in a pdf document can be found here https://github.com/gjmaeda/LocalTimeWarping If you find the code useful and use it in your work you can cite this paper Attach:Team/PubGJMaeda/gjm_2016_AURO_c.pdf
Motion Planning via Stochastic Trajectory Optimization
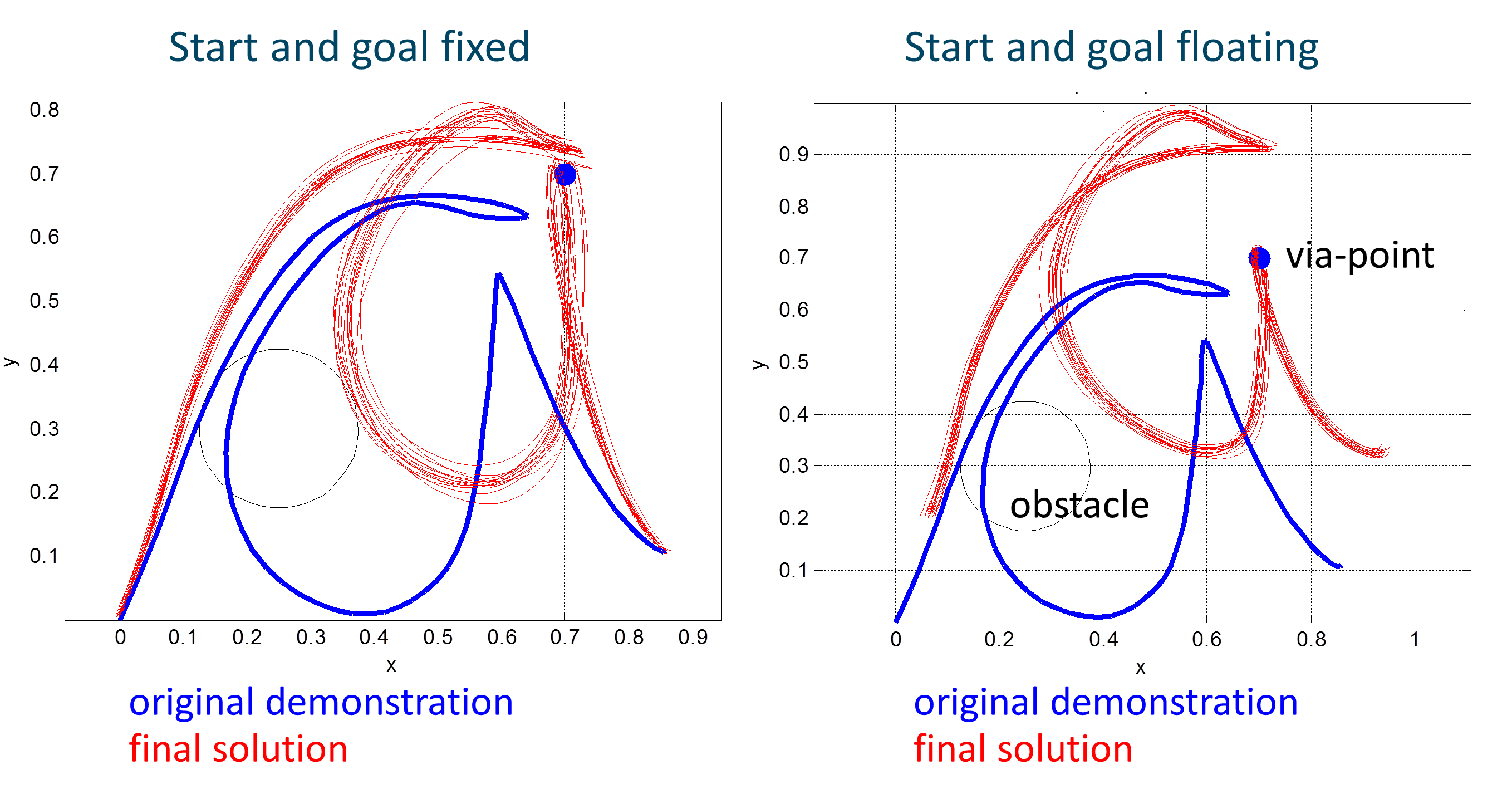
This is a minimalist code in Matlab that uses stochastic optimization for motion planning. It is inspired by a few methods: it uses the exploration of parameters proposed in STOMP, with code based on the Pi2 implementation and the efficiency of REPS as a stochastic optimizer. Despite the code being inspired by different methods, I tried to make its structure as simple as possible. Part of it is because it does not need the DMPs of Pi2 (as in STOMP), and because the episodic version of REPS can be implemented in a few lines of code. Perhaps, the main advantage is the fact that you do not need gradients, and the method works even when the cost is badly behaved, with plateaus and discontinuities. The code that you can find here will run in two different modes. In the first run, the start and goal states are anchored. In the second run, the start and goal are free to float, which allows the solution to preserve more of the original starting shape. Although the latter may sound a bit weird condition (why do you want start/goal to float?) it can be useful to solve the problem described in this paper (which you can also cite if you use the code).
Past PhD Research
Field robotics: iterative learning control and robust observers for autonomous excavation (:youtube HZ9HYnoFof8:)
Related publications:
-
- Maeda, G. J.; Manchester, I. & Rye, D (2015). Combined ILC and Disturbance Observer for the Rejection of Near-Repetitive Disturbances, with Application to Excavation, IEEE Transactions on Control Systems Technology, 23, pp.1754 - 1769 , IEEE.
-
- Maeda, G.; Rye, D. & Singh, S. (2014). Iterative Autonomous Excavation, Field and Service Robotics: Results of the 8th International Conference, 92, pp.369--382, Springer Tracts in Advanced Robotics.
Shortcutting kinodynamic planning with feedback control (:youtube g1sONzWY3vM:)
Related publications:
-
- Maeda, G. J. and Singh, S. P. N. and Durrant-Whyte, H. (2010). Feedback motion planning approach for nonlinear control using gain scheduled RRTs, Proceedings of the 2010 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pp.119--126.