
Probabilistic Optimization
Probabilistic optimization is a pivotal concept in machine learning research, providing a robust framework for making decisions under uncertainty and optimizing complex functions. Central to this approach is the use of maximum entropy methods, which seek the most unbiased inferences in the presence of partial knowledge, thereby maximizing uncertainty and ensuring the most generalizable and robust solutions. Bayesian optimization further enhances this landscape by efficiently optimizing objective functions that are costly to evaluate, leveraging a probabilistic model to predict outcomes and iteratively update the model based on observed data, thereby balancing exploration and exploitation. Additionally, the integration of curriculum learning, where learning tasks are gradually introduced in an increasing order of difficulty, mirrors the way humans learn, allowing for more efficient learning processes and quicker convergence to optimal solutions. Together, these methods provide a comprehensive and powerful toolkit for tackling some of the most challenging problems in robot learning, where the stakes are high and the need for precision and reliability is paramount.
Bayesian Optimization
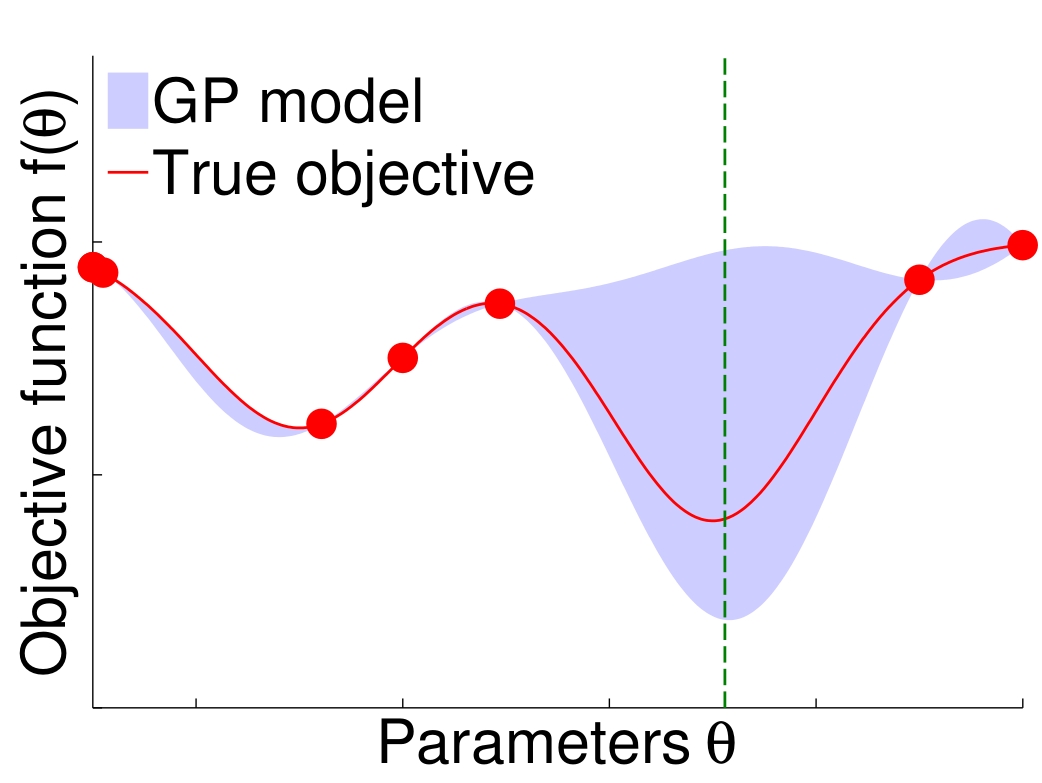
Bayesian optimization is a powerful black-box optimization technique that achieves sample efficiency through principled exploration strategies. We are interested in using these techniques to advance policy search, system identification and hyperparameter optimization more generally.
- Calandra, R.; Seyfarth, A.; Peters, J.; Deisenroth, M. (2015). Bayesian Optimization for Learning Gaits under Uncertainty, Annals of Mathematics and Artificial Intelligence (AMAI).
- Muratore, F.; Eilers, C.; Gienger, M.; Peters, J. (2021). Data-efficient Domain Randomization with Bayesian Optimization, IEEE Robotics and Automation Letters (RA-L), with Presentation at the IEEE International Conference on Robotics and Automation (ICRA), IEEE.
- Cowen-Rivers, A.; Lyu, W.; Tutunov, R.; Wang, Z.; Grosnit, A.; Griffiths, R.R.; Maraval, A.; Jianye, H.; Wang, J.; Peters, J.; Bou Ammar, H. (2022). HEBO: An Empirical Study of Assumptions in Bayesian Optimisation, Journal of Artificial Intelligence Research, 74, pp.1269-1349.
- Bottero, A.G.; Luis, C.E.; Vinogradska, J.; Berkenkamp, F.; Peters, J. (2022). Information-Theoretic Safe Exploration with Gaussian Processes, Advances in Neural Information Processing Systems (NIPS / NeurIPS).
Entropy-regularized Optimization
Distributionally Robust Trajectory Optimization Under Uncertain Dynamics via Relative Entropy Trust-Regions

Trajectory optimization and model predictive control are essential techniques underpinning advanced robotic applications, ranging from autonomous driving to full-body humanoid control. State-of-the-art algorithms have focused on data-driven approaches that infer the system dynamics online and incorporate posterior uncertainty during planning and control. Despite their success, such approaches are still susceptible to catastrophic errors that may arise due to statistical learning biases, unmodeled disturbances, or even directed adversarial attacks. In this paper, we tackle the problem of dynamics mismatch and propose a distributionally robust optimal control formulation that alternates between two relative entropy trust-region optimization problems. Our method finds the worst-case maximum entropy Gaussian posterior over the dynamics parameters and the corresponding robust policy. Furthermore, we show that our approach admits a closed-form backward-pass for a certain class of systems. Finally, we demonstrate the resulting robustness on linear and nonlinear numerical examples.
- Abdulsamad, H.; Dorau, T.; Belousov, B.; Zhu, J.-J; Peters, J. (2021). Distributionally Robust Trajectory Optimization Under Uncertain Dynamics via Relative Entropy Trust-Regions, arXiv.
Entropic Regularization of Markov Decision Processes
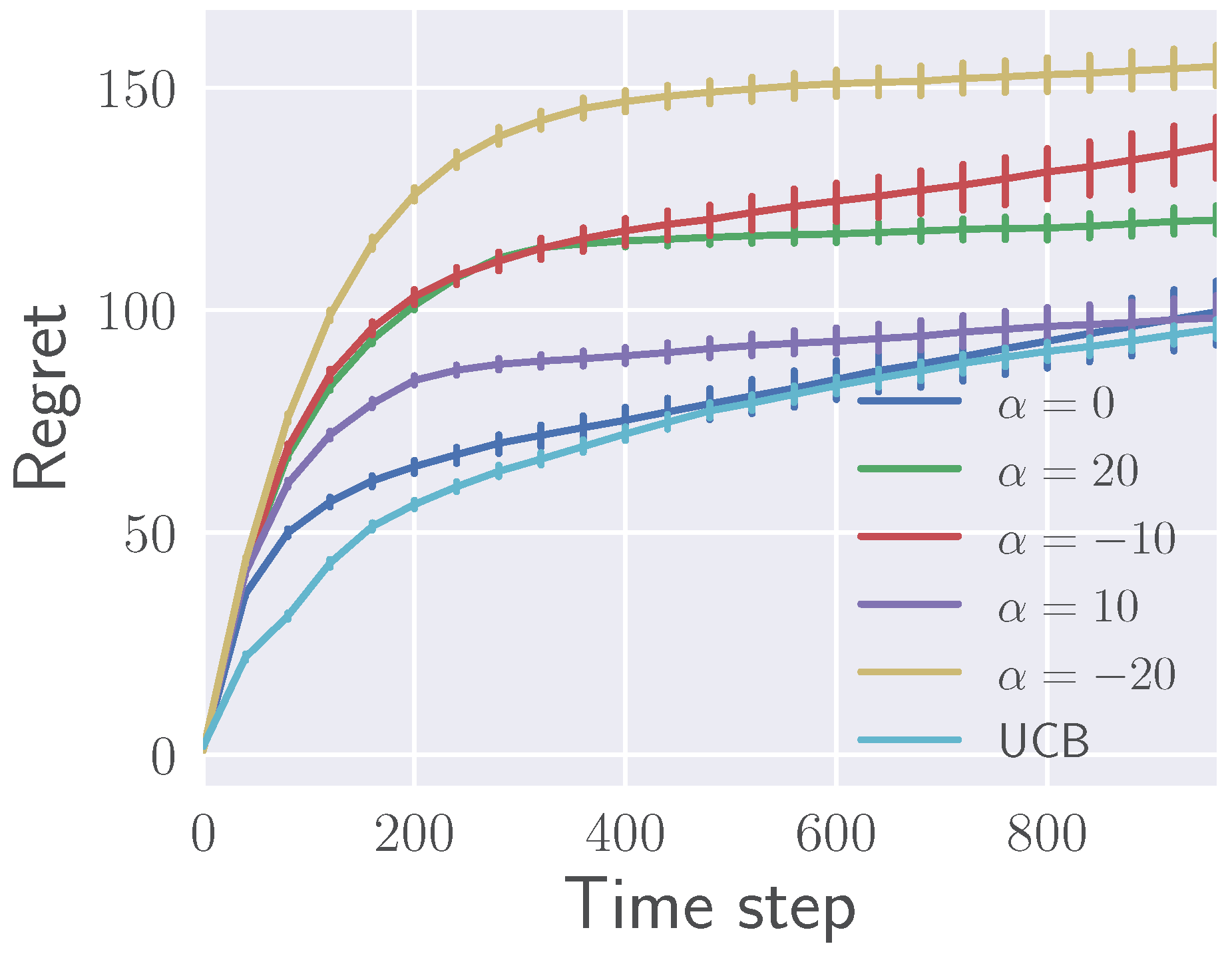
An optimal feedback controller for a given Markov decision process (MDP) can in principle be synthesized by value or policy iteration. However, if the system dynamics and the reward function are unknown, a learning agent must discover an optimal controller via direct interaction with the environment. Such interactive data gathering commonly leads to divergence towards dangerous or uninformative regions of the state space unless additional regularization measures are taken. Prior works proposed bounding the information loss measured by the Kullback–Leibler (KL) divergence at every policy improvement step to eliminate instability in the learning dynamics. In this paper, we consider a broader family of f-divergences, and more concretely 𝛼-divergences, which inherit the beneficial property of providing the policy improvement step in closed form at the same time yielding a corresponding dual objective for policy evaluation. Such entropic proximal policy optimization view gives a unified perspective on compatible actor-critic architectures. In particular, common least-squares value function estimation coupled with advantage-weighted maximum likelihood policy improvement is shown to correspond to the Pearson 𝜒2-divergence penalty. Other actor-critic pairs arise for various choices of the penalty-generating function f. On a concrete instantiation of our framework with the 𝛼-divergence, we carry out asymptotic analysis of the solutions for different values of 𝛼 and demonstrate the effects of the divergence function choice on common standard reinforcement learning problems.
- Belousov, B.; Peters, J. (2019). Entropic Regularization of Markov Decision Processes, Entropy, 21, 7, MDPI.
Curriculum Learning
Self-paced contextual reinforcement learning
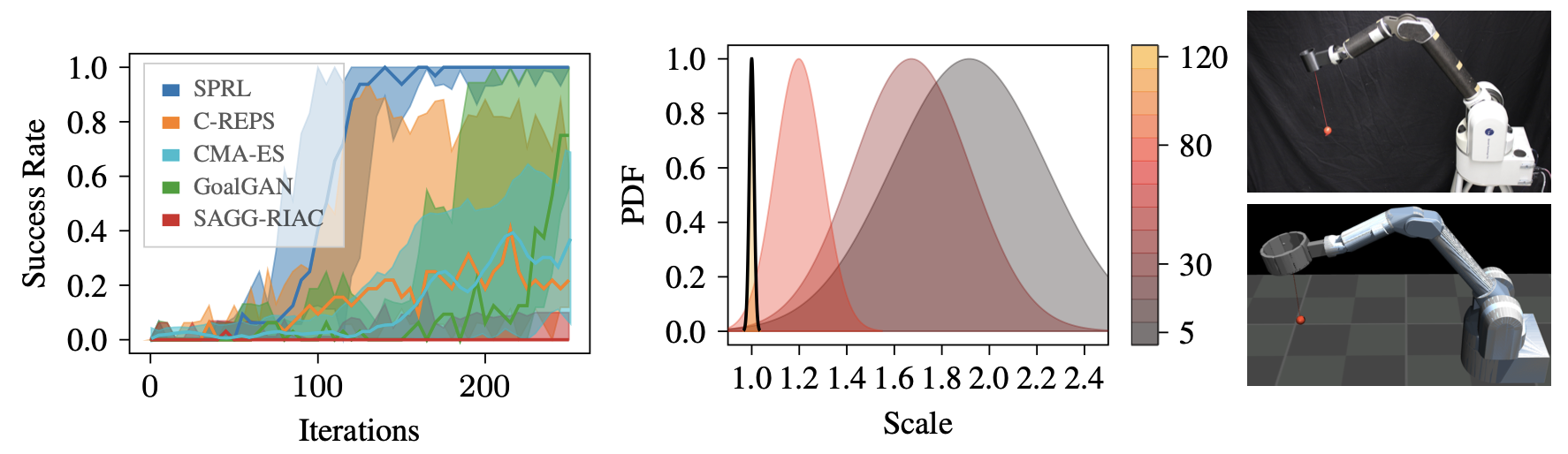
Generalization and adaptation of learned skills to novel situations is a core requirement for intelligent autonomous robots. Although contextual reinforcement learning provides a principled framework for learning and generalization of behaviors across related tasks, it generally relies on uninformed sampling of environments from an unknown, uncontrolled context distribution, thus missing the benefits of structured, sequential learning. We introduce a novel relative entropy reinforcement learning algorithm that gives the agent the freedom to control the intermediate task distribution, allowing for its gradual progression towards the target context distribution. Empirical evaluation shows that the proposed curriculum learning scheme drastically improves sample efficiency and enables learning in scenarios with both broad and sharp target context distributions in which classical approaches perform sub-optimally.
- Klink, P.; Abdulsamad, H.; Belousov, B.; Peters, J. (2019). Self-Paced Contextual Reinforcement Learning, Proceedings of the 3rd Conference on Robot Learning (CoRL).