Reinforcement Learning 

Reinforcement learning (RL) is a powerful machine learning paradigm that enables agents to learn optimal behavior through interactions with an environment. This ability to learn from experience makes RL particularly well-suited for tasks that are difficult or impossible to pre-program, such as playing games, navigating complex environments, and controlling robotic systems. Meanwhile, traditional robotics relies on pre-programmed instructions with limiting adaptability. RL methods can enable robots to learn from experience and adapt to changing environments. Along with using RL for specific tasks like manipulation and locomotion, our research group is at the forefront of RL research, developing new general algorithms and improving techniques that enable agents to learn more efficiently and effectively for various tasks.
To get a quick introduction to reinforcement learning in robotics, do look at our survey Reinforcement Learning in Robotics. Reinforcement learning offers to robotics a framework and set of tools for the design of sophisticated and hard-to-engineer behaviors. Conversely, the challenges of robotic problems provide both inspiration, impact, and validation for developments in reinforcement learning. The relationship between disciplines has sufficient promise to be likened to that between physics and mathematics. In this article, we attempt to strengthen the links between the two research communities by providing a survey of work in reinforcement learning for behavior generation in robots. We highlight both key challenges in robot reinforcement learning as well as notable successes. We discuss how contributions tamed the complexity of the domain and study the role of algorithms, representations, and prior knowledge in achieving these successes. As a result, a particular focus of our paper lies on the choice between model-based and model-free as well as between value function-based and policy search methods. By analyzing a simple problem in some detail we demonstrate how reinforcement learning approaches may be profitably applied, and we note throughout open questions and the tremendous potential for future research.
- Kober, J.; Bagnell, D.; Peters, J. (2013). Reinforcement Learning in Robotics: A Survey, International Journal of Robotics Research (IJRR), 32, 11, pp.1238-1274.
Model-Based RL 
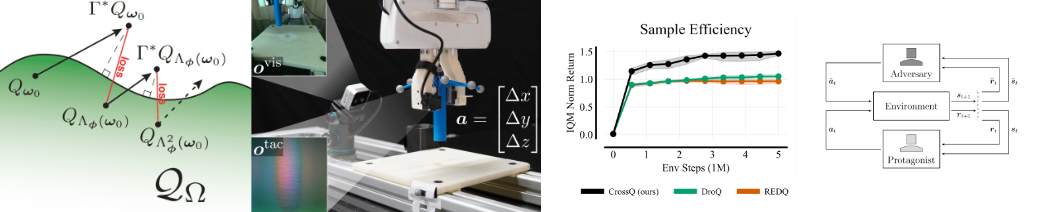
Diminishing Return of Value Expansion Methods in Model-Based Reinforcement Learning. Model-based reinforcement learning is one approach to increase sample efficiency. However, the accuracy of the dynamics model and the resulting compounding error over modelled trajectories are commonly regarded as key limitations. A natural question to ask is: How much more sample efficiency can be gained by improving the learned dynamics models? Our paper empirically answers this question for the class of model-based value expansion methods in continuous control problems. Value expansion methods should benefit from increased model accuracy by enabling longer rollout horizons and better value function approximations. Our empirical study, which leverages oracle dynamics models to avoid compounding model errors, shows that (1) longer horizons increase sample efficiency, but the gain in improvement decreases with each additional expansion step, and (2) the increased model accuracy only marginally increases the sample efficiency compared to learned models with identical horizons. Therefore, longer horizons and increased model accuracy yield diminishing returns in terms of sample efficiency. These improvements in sample efficiency are particularly disappointing when compared to model-free value expansion methods. Even though they introduce no computational overhead, we find their performance to be on-par with model-based value expansion methods. Therefore, we conclude that the limitation of model-based value expansion methods is not the model accuracy of the learned models. While higher model accuracy is beneficial, our experiments show that even a perfect model will not provide an un-rivalled sample efficiency but that the bottleneck lies elsewhere.
- Palenicek, D.; Lutter, M.; Carvalho, J.; Peters, J. (2023). Diminishing Return of Value Expansion Methods in Model-Based Reinforcement Learning, International Conference on Learning Representations (ICLR).
- Palenicek, D.; Lutter, M., Peters, J. (2022). Revisiting Model-based Value Expansion, Multi-disciplinary Conference on Reinforcement Learning and Decision Making (RLDM).
Value-Based Methods
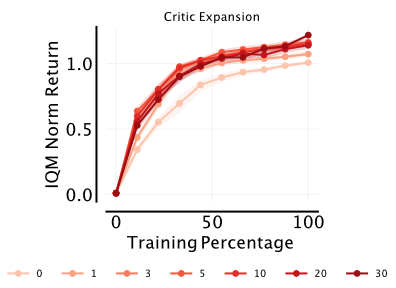
XQC: Well-conditioned Optimization Accelerates Deep Reinforcement Learning. Sample efficiency is a central property of effective deep reinforcement learning algorithms. Recent work has improved this through added complexity, such as larger models, exotic network architectures, and more complex algorithms, which are typically motivated purely by empirical performance. We take a more principled approach by focusing on the optimization landscape of the critic network. Using the eigenspectrum and condition number of the critic’s Hessian, we systematically investigate the impact of common architectural design decisions on training dynamics. Our analysis reveals that a novel combination of batch normalization (bn), weight normalization (wn), and a distributional cross-entropy (ce) loss produces condition numbers orders of magnitude smaller than baselines. This combination also naturally bounds gradient norms, a property critical for maintaining a stable effective learning rate under non-stationary targets and bootstrapping. Based on these insights, we introduce xqc: a well-motivated, sample-efficient deep actor-critic algorithm built upon soft actor-critic that embodies these optimization-aware principles. We achieve state-of-the-art sample efficiency across 55 proprioception and 15 vision-based continuous control tasks, all while using significantly fewer parameters than competing methods.
- Palenicek, D.; Vogt, F.; Watson, J.; Posner, I.; Peters, J. (2026). XQC: Well-conditioned Optimization Accelerates Deep Reinforcement Learning, International Conference on Learning Representations (ICLR).

Scaling Off-Policy Reinforcement Learning with Batch and Weight Normalization. Reinforcement learning has achieved significant milestones, but sample efficiency remains a bottleneck for real-world applications. Recently, CrossQ has demonstrated state-of-the-art sample efficiency with a low update-to-data (utd) ratio of 1. In this work, we explore CrossQ’s scaling behavior with higher utd ratios. We identify challenges in the training dynamics, which are emphasized by higher utd ratios. To address these, we integrate weight normalization into the CrossQ framework, a solution that stabilizes training, has been shown to prevent potential loss of plasticity and keeps the effective learning rate constant. Our proposed approach reliably scales with increasing utd ratios, achieving competitive performance across 25 challenging continuous control tasks on the DeepMind Control Suite and MyoSuite benchmarks, notably the complex dog and humanoid environments. This work eliminates the need for drastic interventions, such as network resets, and offers a simple yet robust pathway for improving sample efficiency and scalability in model-free reinforcement learning.
- Palenicek, D.; Vogt, F.; Watson, J.; Peters, J. (2025). CrossQ+WN: Scaling Off-Policy Reinforcement Learning with Batch and Weight Normalization, European Workshop on Reinforcement Learning (EWRL).
- Palenicek, D.; Vogt, F.; Watson, J.; Peters, J. (2025). Scaling Off-Policy Reinforcement Learning with Batch and Weight Normalization, Advances in Neural Information Processing Systems (NeurIPS).
- Palenicek, D.; Vogt, F.; Peters, J. (2025). Scaling CrossQ with Weight Normalization, Multi-disciplinary Conference on Reinforcement Learning and Decision Making (RLDM).
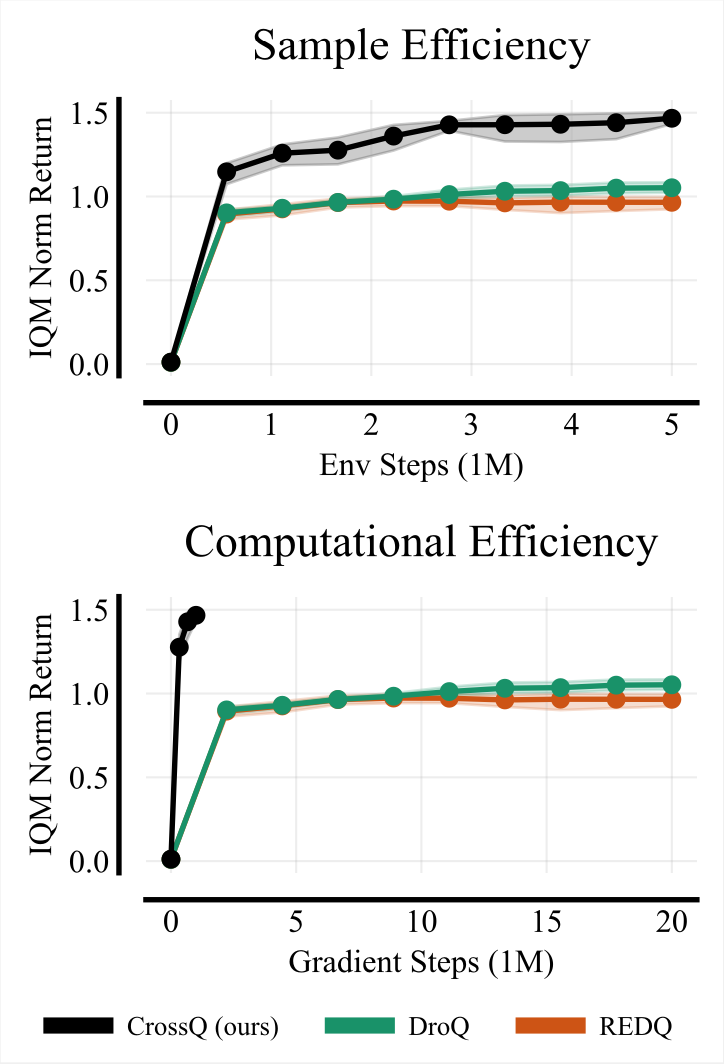
CrossQ: Batch Normalisation in Deep Reinforcement Learning for Greater Sample Efficiency and Simplicity. Sample efficiency is a crucial problem in deep reinforcement learning. Recent algorithms, such as REDQ and DroQ, found a way to improve the sample efficiency by increasing the update-to-data (UTD) ratio to 20 gradient update steps on the critic per environment sample. However, this comes at the expense of a greatly increased computational cost. To reduce this computational burden, we introduce CrossQ: a lightweight algorithm that makes careful use of Batch Normalization and removes target networks to surpass the state-of-the-art in sample efficiency while maintaining a low UTD ratio of 1. Notably, CrossQ does not rely on advanced bias-reduction schemes used in current methods.
CrossQ’s contributions are thus threefold:
(1) state-of-the-art sample efficiency,
(2) substantial reduction in computational cost compared to REDQ and DroQ, and
(3) ease of implementation, requiring just a few lines of code on top of SAC.
Parameterized Projected Bellman Operator. Approximate value iteration (AVI) is a family of algorithms for reinforcement learning (RL) that aims to obtain an approximation of the optimal value function. Generally, AVI algorithms implement an iterated procedure where each step consists of (i) an application of the Bellman operator and (ii) a projection step into a considered function space. Notoriously, the Bellman operator leverages transition samples, which strongly determine its behavior, as uninformative samples can result in negligible updates or long detours, whose detrimental effects are further exacerbated by the computationally intensive projection step. To address these issues, we propose a novel alternative approach based on learning an approximate version of the Bellman operator rather than estimating it through samples as in AVI approaches. This way, we are able to (i) generalize across transition samples and (ii) avoid the computationally intensive projection step. For this reason, we call our novel operator projected Bellman operator (PBO).
- Vincent, T.; Metelli, A.; Belousov, B.; Peters, J.; Restelli, M.; D'Eramo, C. (2024). Parameterized Projected Bellman Operator, Proceedings of the National Conference on Artificial Intelligence (AAAI).
- Vincent, T.; Metelli, A.; Peters, J.; Restelli, M.; D'Eramo, C. (2023). Parameterized projected Bellman operator, ICML Workshop on New Frontiers in Learning, Control, and Dynamical Systems.
Robust RL
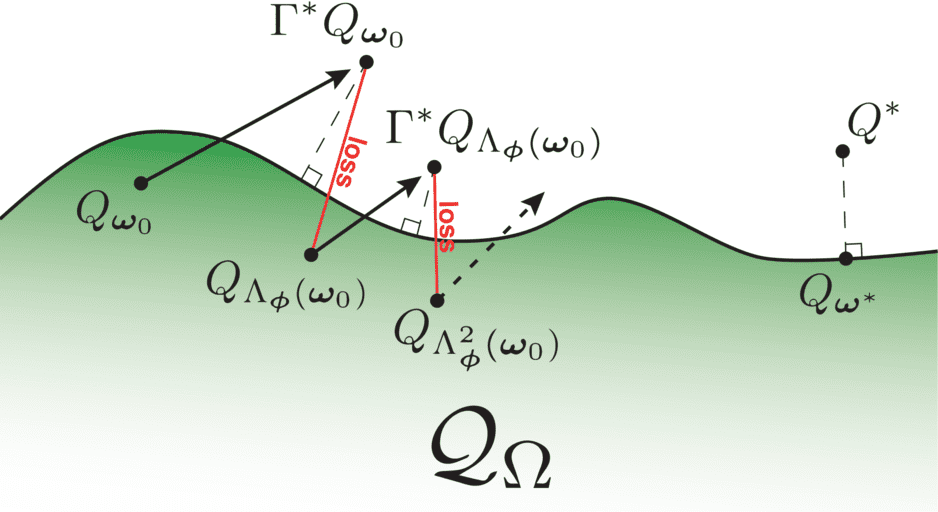
Reinforcement learning (RL) has become a highly successful framework for learning in Markov decision processes (MDP). Due to the adoption of RL in realistic and complex environments, solution robustness becomes an increasingly important aspect of RL deployment. Nevertheless, current RL algorithms struggle with robustness to uncertainty, disturbances, or structural changes in the environment. In our survey Robust Reinforcement Learning, we provide an overview of the literature and categorize these methods in four different ways: (i) Transition robust designs account for uncertainties in the system dynamics by manipulating the transition probabilities between states; (ii) Disturbance robust designs leverage external forces to model uncertainty in the system behavior; (iii) Action robust designs redirect transitions of the system by corrupting an agent’s output; (iv) Observation robust designs exploit or distort the perceived system state of the policy. Each of these robust designs alters a different aspect of the MDP. Additionally, we address the connection of robustness to the risk-based and entropy-regularized RL formulations.
- Hansel, K.; Moos, J.; Abdulsamad, H.; Stark, S.; Clever, D.; Peters, J. (2022). Robust Reinforcement Learning: A Review of Foundations and Recent Advances, Machine Learning and Knowledge Extraction (MAKE), 4, 1, pp.276--315, MDPI.

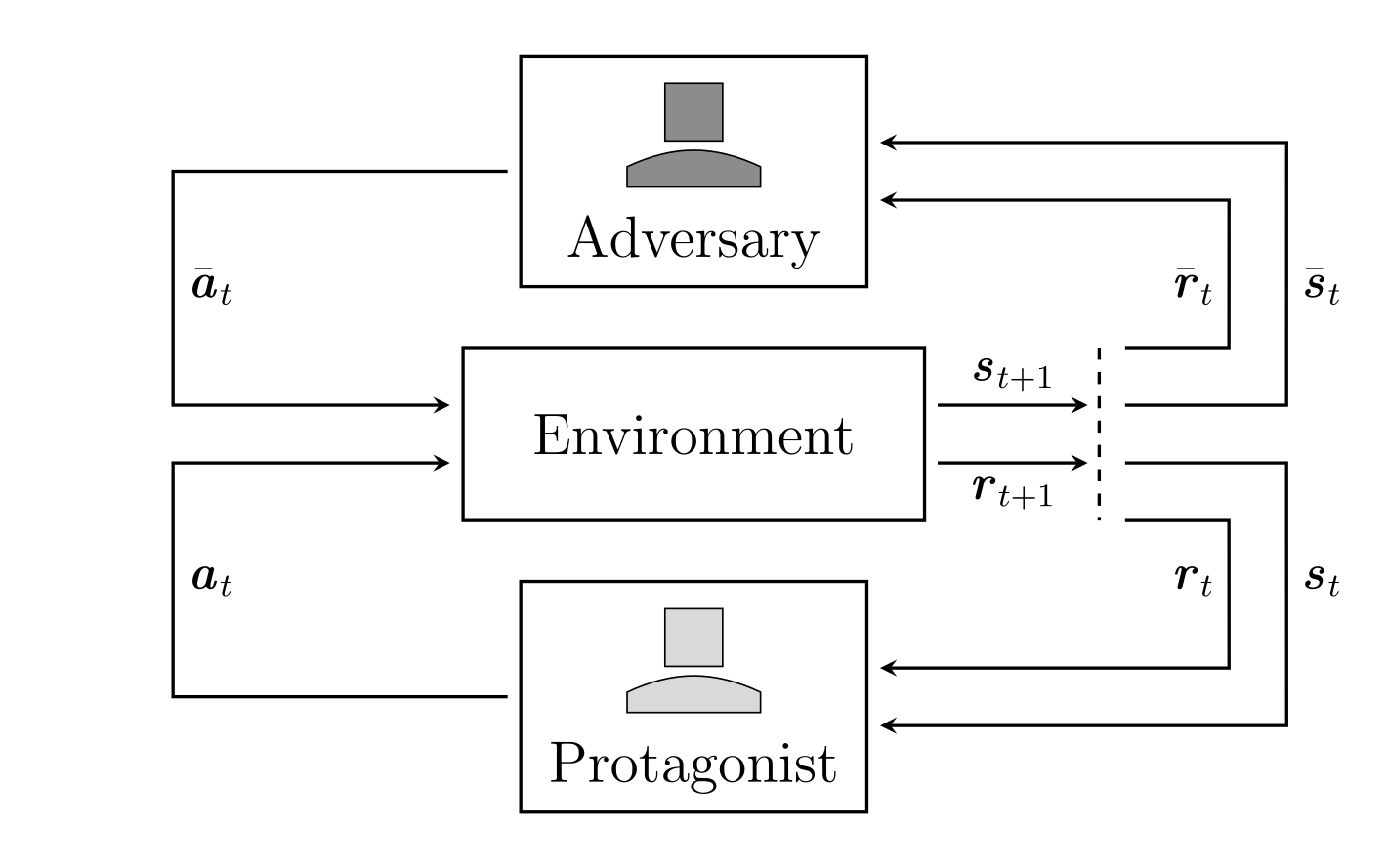
Robust Adversarial Reinforcement Learning via Bounded Rationality Curricula. Robust Adversarial Reinforcement Learning (RARL) trains a protagonist against destabilizing forces exercised by an adversary in a competitive zero-sum Markov game, whose optimal solution corresponds to a Nash equilibrium, eliciting robustness in the trained agent. However, finding Nash equilibria requires facing complex saddle point optimization problems, which can be prohibitive to solve. In this paper, we propose a novel approach to ease the complexity of the saddle point optimization problem. We show that the solution of this entropy-regularized problem corresponds to a Quantal Response Equilibrium (QRE), a generalization of Nash equilibria that accounts for bounded rationality, and a connection between the entropy-regularized RL objective and QRE enables free modulation of the rationality of the agents by simply tuning the temperature coefficient. We leverage this insight to propose our novel algorithm, Quantal Adversarial RL (QARL), which gradually increases the rationality of the adversary in a curriculum fashion until it is fully rational, easing the complexity of the optimization problem while retaining robustness.
- Reddi, A.; Toelle, M.; Peters, J.; Chalvatzaki, G.; D'Eramo, C. (2024). Robust Adversarial Reinforcement Learning via Bounded Rationality Curricula, International Conference on Learning Representations (ICLR), Spotlight.
Multi-Agent RL

Disentangling Interaction using Maximum Entropy Reinforcement Learning in Multi-Agent Systems. Research on multi-agent interaction involving both multiple artificial agents and humans is still in its infancy. Most recent approaches have focused on environments with collaboration-focused human behavior, or providing only a small, defined set of situations. When deploying robots in human-inhabited environments in the future, it will be unlikely that all interactions fit a predefined model of collaboration, where collaborative behavior is still expected from the robot. Existing approaches are unlikely to effectively create such behaviors in such "coexistence" environments. To tackle this issue, we introduce a novel framework that decomposes interaction and task-solving into separate learning problems and blends the resulting policies at inference time. Policies are learned with maximum entropy reinforcement learning, allowing us to create interaction-impact-aware agents and scale the cost of training agents linearly with the number of agents and available tasks. We propose a weighting function covering the alignment of interaction distributions with the original task. We demonstrate that our framework addresses the scaling problem while solving a given task and considering collaboration opportunities in a co-existence particle environment and a new cooking environment. Our work introduces a new learning paradigm that opens the path to more complex multi-robot, multi-human interactions.
- Rother, D.; Weisswange, T.H.; Peters, J. (2023). Disentangling Interaction using Maximum Entropy Reinforcement Learning in Multi-Agent Systems, European Conference on Artificial Intelligence (ECAI).
Multi-Task RL
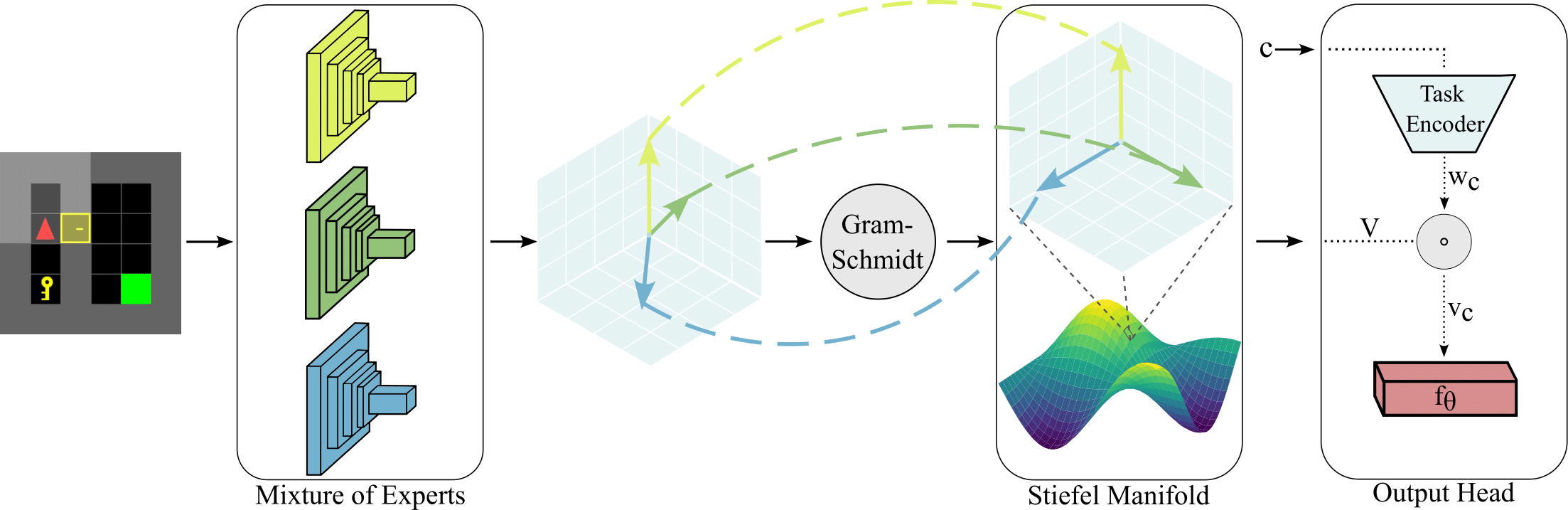
Multi-Task Reinforcement Learning with Mixture of Orthogonal Experts. Multi-Task Reinforcement Learning (MTRL) tackles the long-standing problem of endowing agents with skills that generalize across a variety of problems. To this end, sharing representations plays a fundamental role in capturing both unique and common characteristics of the tasks. Tasks may exhibit similarities in terms of skills, objects, or physical properties while leveraging their representations eases the achievement of a universal policy. Nevertheless, the pursuit of learning a shared set of diverse representations is still an open challenge. In this paper, we introduce a novel approach for representation learning in MTRL that encapsulates common structures among the tasks using orthogonal representations to promote diversity. Our method, named Mixture Of Orthogonal Experts (MOORE), leverages a Gram-Schmidt process to shape a shared subspace of representations generated by a mixture of experts. When task-specific information is provided, MOORE generates relevant representations from this shared subspace. We assess the effectiveness of our approach on two MTRL benchmarks, namely MiniGrid and MetaWorld, showing that MOORE surpasses related baselines and establishes a new state-of-the-art result on MetaWorld.
- Hendawy, A.; Peters, J.; D'Eramo, C. (2024). Multi-Task Reinforcement Learning with Mixture of Orthogonal Experts, International Conference on Learning Representations (ICLR).
Policy Search
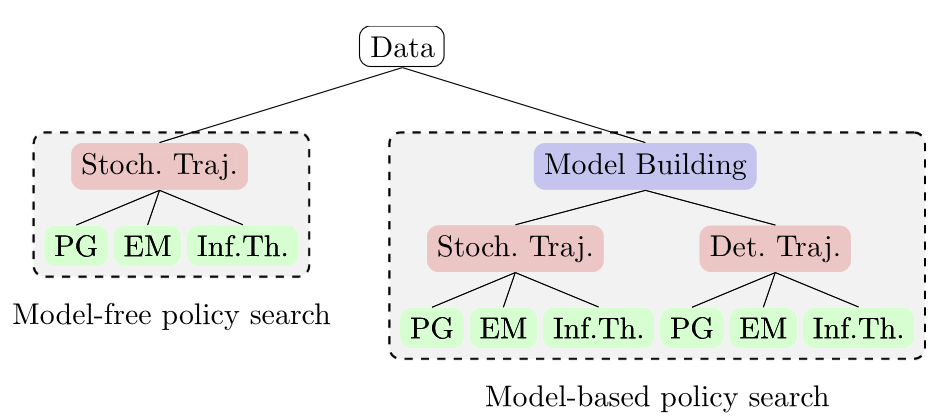
Policy search is a subfield in reinforcement learning which focuses on finding good parameters for a given policy parametrization. It is well suited for robotics as it can cope with high-dimensional state and action spaces, one of the main challenges in robot learning. In our survey Policy Search for Robotics, we review recent successes of both model-free and model-based policy search in robot learning. Model-free policy search is a general approach to learn policies based on sampled trajectories. We classify model-free methods based on their policy evaluation strategy, policy update strategy, and exploration strategy and present a unified view on existing algorithms. Learning a policy is often easier than learning an accurate forward model, and, hence, model-free methods are more frequently used in practice. However, for each sampled trajectory, it is necessary to interact with the robot, which can be time-consuming and challenging in practice. Model-based policy search addresses this problem by first learning a simulator of the robot’s dynamics from data. Subsequently, the simulator generates trajectories that are used for policy learning. For both model-free and model-based policy search methods, we review their respective properties and their applicability to robotic systems. If you want to learn more, do look into our survey:
- Deisenroth, M. P.; Neumann, G.; Peters, J. (2013). A Survey on Policy Search for Robotics, Foundations and Trends in Robotics, 21, pp.388-403.
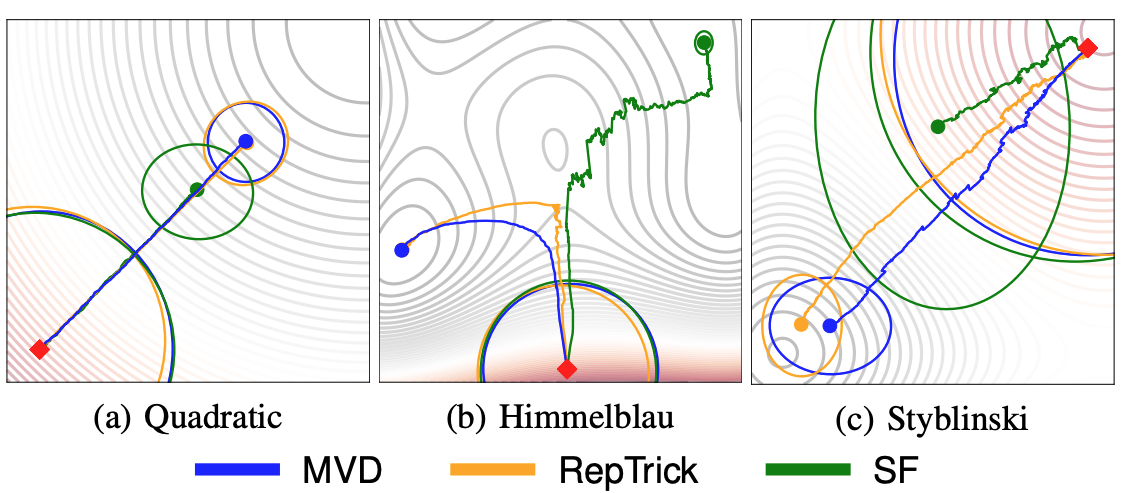
An Empirical Analysis of Measure-Valued Derivatives for Policy Gradients. Reinforcement learning methods for robotics are increasingly successful due to the constant development of better policy gradient techniques. A precise (low variance) and accurate (low bias) gradient estimator is crucial to face increasingly complex tasks. Traditional policy gradient algorithms use the likelihood-ratio trick, which is known to produce unbiased but high variance estimates. More modern approaches exploit the reparametrization trick, which gives lower variance gradient estimates but requires differentiable value function approximations. In this work, we study a different type of stochastic gradient estimator: the Measure-Valued Derivative. This estimator is unbiased, has low variance, and can be used with differentiable and non-differentiable function approximators. We empirically evaluate this estimator in the actor-critic policy gradient setting and show that it can reach comparable performance with methods based on the likelihood-ratio or reparametrization tricks, both in low and high-dimensional action spaces.
- Carvalho, J., Tateo, D., Muratore, F., Peters, J. (2021). An Empirical Analysis of Measure-Valued Derivatives for Policy Gradients, International Joint Conference on Neural Networks (IJCNN).
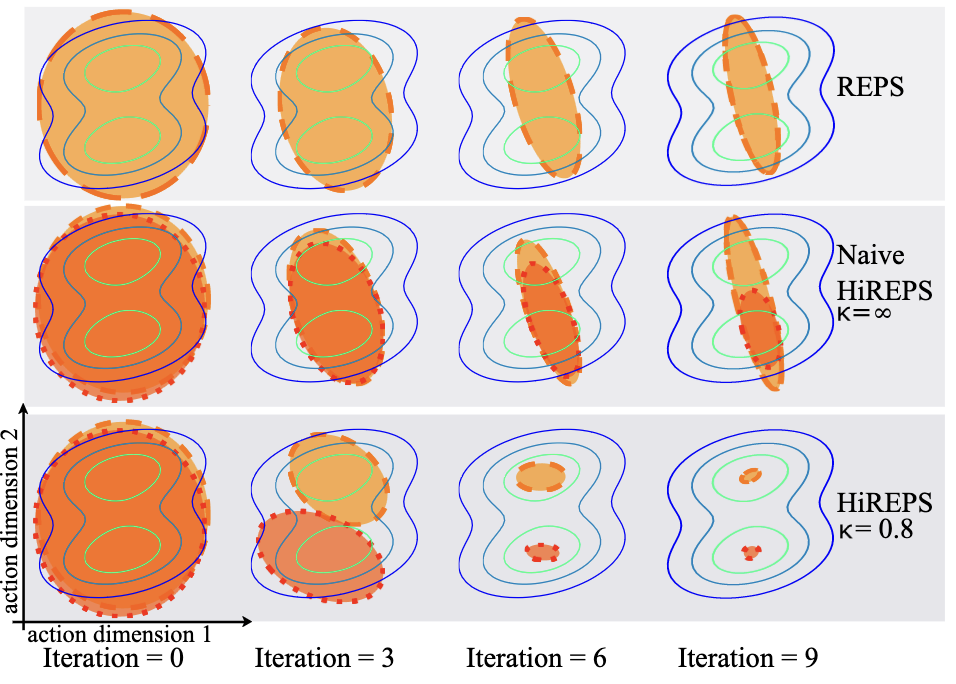
(Hierarchical) Relative Entropy Policy Search. We introduce Relative Entropy Policy Search (REPS) and its hierarchical extension, Hierarchical REPS (HiREPS), two novel policy search algorithms that significantly advance reinforcement learning for complex robotic tasks. REPS formulates policy optimization as a constrained optimization problem, maximizing expected return while bounding information loss between updates using relative entropy. This approach yields an exact, stable update step, enhancing sample efficiency and learning stability over traditional policy gradient methods. HiREPS extends this framework to use sub-policies as building blocks of a hierarchical policy. We formulate the problem as a latent variable estimation problem, which can be solved using the EM algorithm. We evaluate both algorithms on challenging robotic tasks such as robot table tennis, tetherball, and robot hockey and show strong performance results.
- Abdulsamad, H.; Naveh, K.; Peters, J. (2019). Model-Based Relative Entropy Policy Search for Stochastic Hybrid Systems, 4th Multidisciplinary Conference on Reinforcement Learning and Decision Making (RLDM).
- Daniel, C.; Neumann, G.; Kroemer, O.; Peters, J. (2016). Hierarchical Relative Entropy Policy Search, Journal of Machine Learning Research (JMLR), 17, pp.1-50.
- Daniel, C.; Neumann, G.; Peters, J. (2012). Hierarchical Relative Entropy Policy Search, Proceedings of the International Conference on Artificial Intelligence and Statistics (AISTATS 2012).
- Daniel, C. (2012). Hierarchical Relative Entropy Policy Search, Masters Thesis.
- Peters, J.; Muelling, K.; Altun, Y. (2010). Relative Entropy Policy Search, Proceedings of the Twenty-Fourth National Conference on Artificial Intelligence (AAAI), Physically Grounded AI Track.
- Peters, J. (2007). Relative Entropy Policy Search, CLMC Technical Report: TR-CLMC-2007-2, University of Southern California.

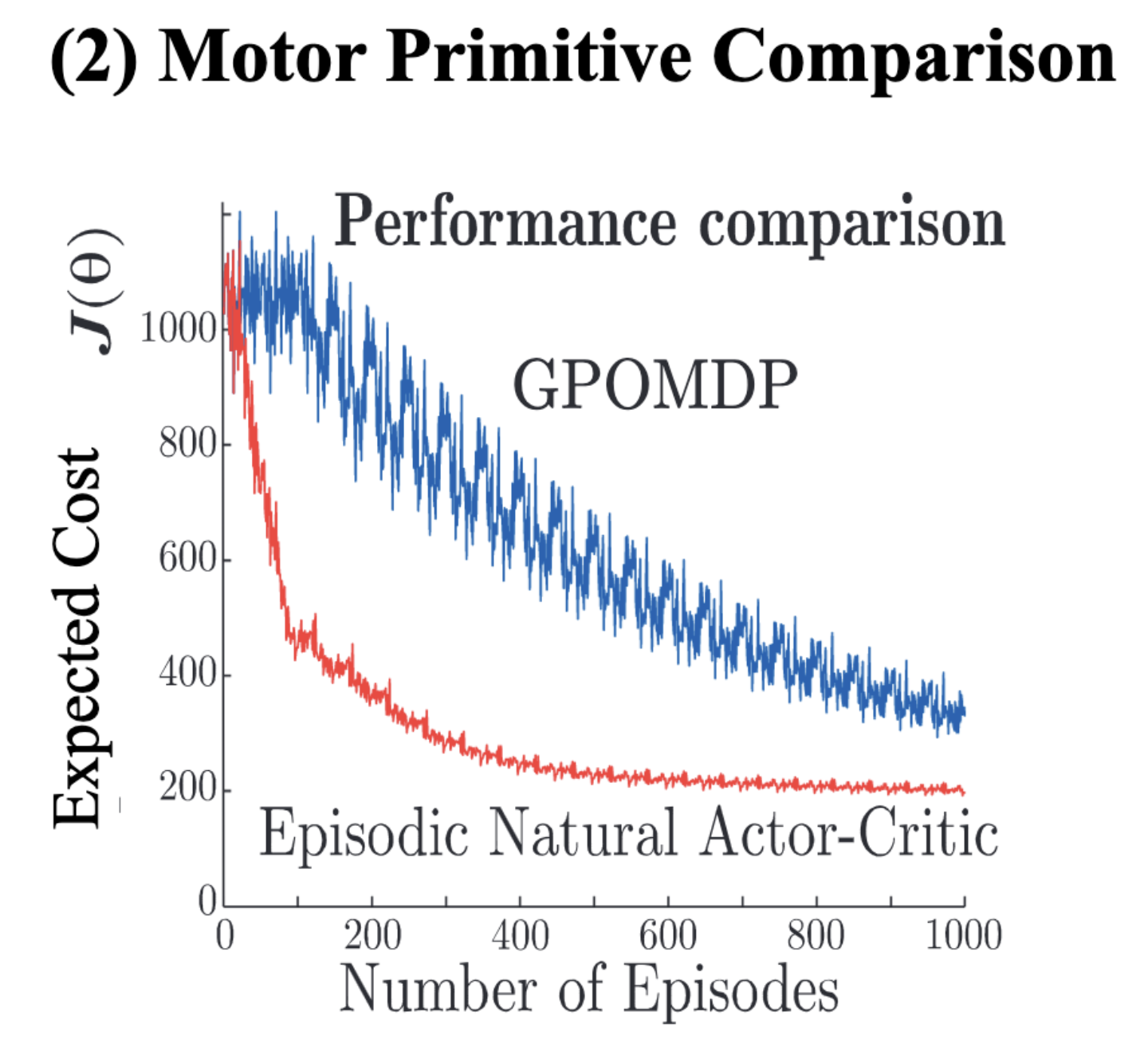
Policy Search for Motor Primitives in Robotics. Many motor skills in humanoid robotics can be learned using parametrized motor primitives. While successful applications to date have been achieved with imitation learning, most of the interesting motor learning problems are high-dimensional reinforcement learning problems. These problems are often beyond the reach of current reinforcement learning methods. In this paper, we study parametrized policy search methods and apply these to benchmark problems of motor primitive learning in robotics. We show that many well-known parametrized policy search methods can be derived from a general, common framework. This framework yields both policy gradient methods and expectation-maximization (EM) inspired algorithms. We introduce a novel EM-inspired algorithm for policy learning that is particularly well-suited for dynamical system motor primitives. We compare this algorithm, both in simulation and on a real robot, to several well-known parametrized policy search methods such as episodic REINFORCE, ‘Vanilla’ Policy Gradients with optimal baselines, episodic Natural Actor Critic, and episodic Reward-Weighted Regression. We show that the proposed method out-performs them on an empirical benchmark of learning dynamical system motor primitives both in simulation and on a real robot. We apply it in the context of motor learning and show that it can learn a complex Ball-in-a-Cup task on a real Barrett WAM™ robot arm.
- Kober, J.; Peters, J. (2011). Policy Search for Motor Primitives in Robotics, Machine Learning (MLJ), 84, 1-2, pp.171-203.
- Kober, J.; Peters, J. (2009). Policy Search for Motor Primitives in Robotics, Advances in Neural Information Processing Systems 22 (NIPS/NeurIPS), Cambridge, MA: MIT Press.
Natural Actor-Critic. In this paper, we suggest a novel reinforcement learning architecture, the Natural Actor-Critic. The actor updates are achieved using stochastic policy gradients employing Amari's natural gradient approach, while the critic obtains both the natural policy gradient and additional parameters of a value function simultaneously by linear regression. We show that actor improvements with natural policy gradients are particularly appealing as these are independent of coordinate frame of the chosen policy representation, and can be estimated more efficiently than regular policy gradients. The critic makes use of a special basis function parameterization motivated by the policy-gradient compatible function approximation. We show that several well-known reinforcement learning methods such as the original Actor-Critic and Bradtke's Linear Quadratic Q-Learning are in fact Natural Actor-Critic algorithms. Empirical evaluations illustrate the effectiveness of our techniques in comparison to previous methods, and also demonstrate their applicability for learning control on an anthropomorphic robot arm.
- Peters, J.; Schaal, S. (2008). Natural actor critic, Neurocomputing, 71, 7-9, pp.1180-1190.