
Imitation Learning
ToDo: Julen, Firas, Joao, Oleg, Max, An
We investigate methods that enable non-expert users to program robots by means of demonstrations. Such imitation learning methods enable the robot to solve a given task in similar style compared to a human, which makes the robot's behavior more predictable and, thus, safer for human-robot interactions. In addition to imitation learning methods, which directly aim to infer the policy from human demonstrations, we also develop methods for inverse reinforcement learning, which aim to infer a reward function as a concise representation of the demonstrated task. Such reward function can enable the robot to better react to changes in the environment, or to better predict the human behavior.
Behavioral Cloning & Deep Generative Models
SE(3)-DiffusionFields: Learning smooth cost functions for joint grasp and motion optimization through diffusion
Multi-objective optimization problems are ubiquitous in robotics, e.g., the optimization of a robot manipulation task requires a joint consideration of grasp pose configurations, collisions and joint limits. While some demands can be easily hand-designed, e.g., the smoothness of a trajectory, several task-specific objectives need to be learned from data. This work introduces a method for learning data-driven SE(3) cost functions as diffusion models. Diffusion models can represent highly-expressive multimodal distributions and exhibit proper gradients over the entire space due to their score-matching training objective. Learning costs as diffusion models allows their seamless integration with other costs into a single differentiable objective function, enabling joint gradient-based motion optimization. In this work, we focus on learning SE(3) diffusion models for 6DoF grasping, giving rise to a novel framework for joint grasp and motion optimization without needing to decouple grasp selection from trajectory generation. We evaluate the representation power of our SE(3) diffusion models w.r.t. classical generative models, and we showcase the superior performance of our proposed optimization framework in a series of simulated and real-world robotic manipulation tasks against representative baselines.
-
- Urain, J.; Funk, N.; Peters, J.; Chalvatzaki G (2023). SE(3)-DiffusionFields: Learning smooth cost functions for joint grasp and motion optimization through diffusion, International Conference on Robotics and Automation (ICRA).
Motion Planning Diffusion: Learning and Planning of Robot Motions with Diffusion Models

Learning priors on trajectory distributions can help accelerate robot motion planning optimization. Given previously successful plans, learning trajectory generative models as priors for a new planning problem is highly desirable. Prior works propose several ways on utilizing this prior to bootstrapping the motion planning problem. Either sampling the prior for initializations or using the prior distribution in a maximum-a-posterior formulation for trajectory optimization. In this work, we propose learning diffusion models as priors. We then can sample directly from the posterior trajectory distribution conditioned on task goals, by leveraging the inverse denoising process of diffusion models. Furthermore, diffusion has been recently shown to effectively encode data multimodality in high-dimensional settings, which is particularly well-suited for large trajectory dataset. To demonstrate our method efficacy, we compare our proposed method - Motion Planning Diffusion - against several baselines in simulated planar robot and 7-dof robot arm manipulator environments. To assess the generalization capabilities of our method, we test it in environments with previously unseen obstacles. Our experiments show that diffusion models are strong priors to encode high-dimensional trajectory distributions of robot motions.
-
- Carvalho, J.; Le, A. T.; Baierl, M.; Koert, D.; Peters, J. (2023). Motion Planning Diffusion: Learning and Planning of Robot Motions with Diffusion Models, IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS).
-
- Carvalho, J.; Baierl, M; Urain, J; Peters, J. (2022). Conditioned Score-Based Models for Learning Collision-Free Trajectory Generation, NeurIPS 2022 Workshop on Score-Based Methods.
Inverse Reinforcement Learning
Least-Squares Inverse Q-Learning
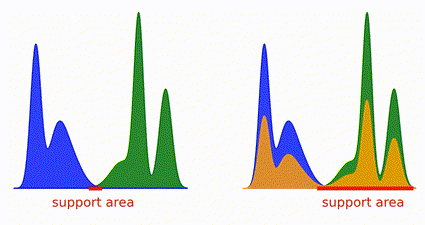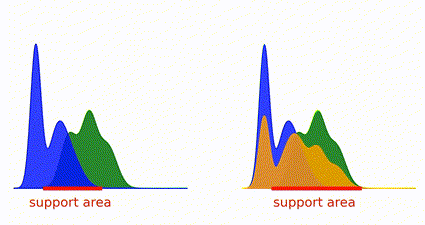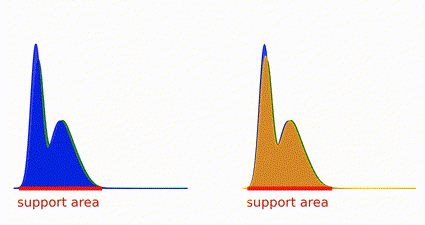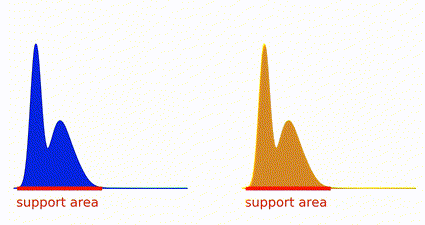
Recent advances in imitation learning have explored learning a Q-function through implicit reward formulation, eschewing explicit reward functions. However, these methods often necessitate implicit reward regularization for stability and struggle with absorbing states. While prior work has suggested the efficacy of squared norm regularization on the implicit reward function, lacking theoretical analysis, our research introduces a novel perspective. By incorporating this regularization within a mixture distribution of the policy and the expert, we elucidate its role in minimizing squared Bellman error and optimizing a bounded χ2-Divergence between the expert and the mixture distribution. This framework addresses instabilities and effectively handles absorbing states. Our proposed approach, Least Squares Inverse Q-Learning (LS-IQ), outperforms existing algorithms, particularly in environments with absorbing states. Additionally, we propose leveraging an inverse dynamics model for learning solely from observations, maintaining performance in scenarios lacking expert actions.
-
- Al-Hafez, F.; Tateo, D.; Arenz, O.; Zhao, G.; Peters, J. (2023). LS-IQ: Implicit Reward Regularization for Inverse Reinforcement Learning, International Conference on Learning Representations (ICLR).
Language-Conditioned Robot Manipulation
A Unifying Perspective on Language-Based Task Representations for Robot Control
Natural language is becoming increasingly important in robot control for both high-level planning and goal-directed conditioning of motor skills. While a number of solutions have been proposed already, it is yet to be seen what architecture will succeed in seamlessly integrating language, vision, and action. To better understand the landscape of existing methods, we propose to view the algorithms from the perspective of “Language-Based Task Representations”, i.e., categorizing the methods that condition robot action generation on natural language commands according to their task representation and embedding architecture. Our proposed taxonomy intuitively groups existing algorithms, highlights their commonalities and distinctions, and suggests directions for further investigation.
-
- Toelle, M.; Belousov, B.; Peters, J. (2023). A Unifying Perspective on Language-Based Task Representations for Robot Control, CoRL Workshop on Language and Robot Learning: Language as Grounding.
-
- Chalvatzaki, G.; Younes, A.; Nandha, D.; Le, A. T.; Ribeiro, L.F.R.; Gurevych, I. (2023). Learning to reason over scene graphs: a case study of finetuning GPT-2 into a robot language model for grounded task planning, in: Dimitrios Kanoulas (eds.), Frontiers in Robotics and AI.
Forceful Imitation Learning
Learning forceful manipulation skills from multi-modal human demonstrations 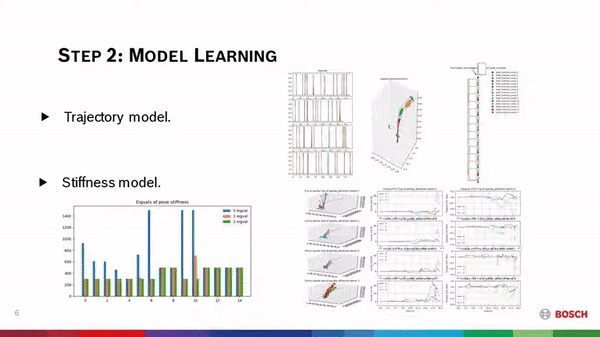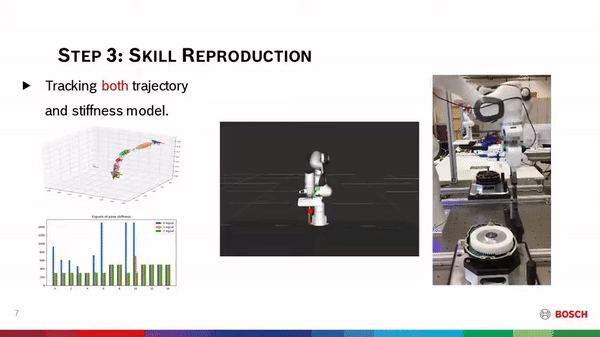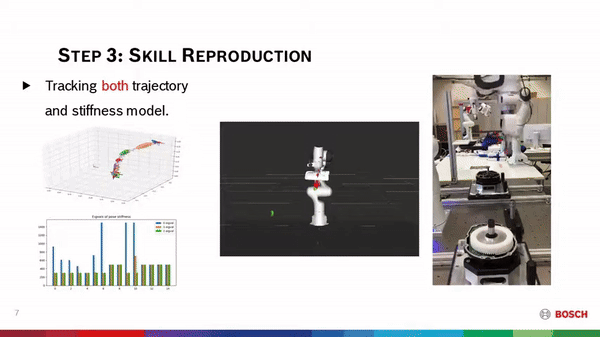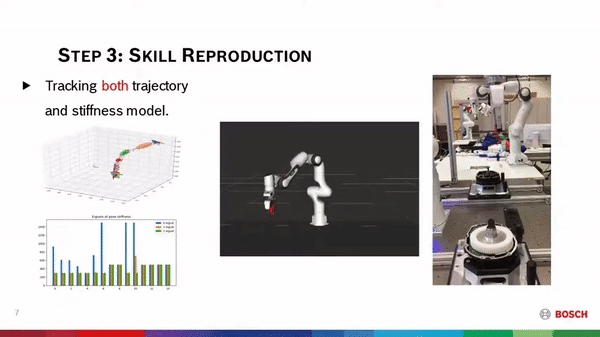 Learning from Demonstration (LfD) provides an intuitive and fast approach to program robotic manipulators. Task-parameterized representations allow easy adaptation to new scenes and online observations. However, this approach has been limited to pose-only demonstrations and thus only skills with spatial and temporal features. We extend the LfD framework to address forceful manipulation skills, which are important for industrial processes such as assembly. For such skills, multi-modal demonstrations, including robot end-effector poses, force and torque readings, and operation scenes, are essential. We aim to reproduce such skills reliably according to the demonstrated pose and force profiles within different scenes.
Learning from Demonstration (LfD) provides an intuitive and fast approach to program robotic manipulators. Task-parameterized representations allow easy adaptation to new scenes and online observations. However, this approach has been limited to pose-only demonstrations and thus only skills with spatial and temporal features. We extend the LfD framework to address forceful manipulation skills, which are important for industrial processes such as assembly. For such skills, multi-modal demonstrations, including robot end-effector poses, force and torque readings, and operation scenes, are essential. We aim to reproduce such skills reliably according to the demonstrated pose and force profiles within different scenes.
-
- Le, A. T.; Guo M.; Duijkeren, N.; Rozo, L.; Krug, R.; Kupcsik, A.G.; Buerger, M. (2021). Learning forceful manipulation skills from multi-modal human demonstrations, IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS).