
Research Overview
Creating autonomous robots that can learn to assist humans in
situations of daily life is a fascinating challenge for machine
learning. While this aim has been a long-standing vision of
artificial intelligence and the cognitive sciences, we have yet
to achieve the first step of creating robots that can learn to
accomplish many different tasks triggered by environmental
context or higher-level instruction.  The goal of our robot learning
laboratory is the investigation of the ingredients for such a
general approach to motor skill learning, to get closer towards
human-like performance in robotics. We thus focus on the solution
of basic problems in robotics while developing domain-appropriate machine-learning methods.
Starting from theoretically well-founded approaches to representing
the required control structures for task representation and
execution, we replace the analytically derived modules by more
flexible, learned ones.
The goal of our robot learning
laboratory is the investigation of the ingredients for such a
general approach to motor skill learning, to get closer towards
human-like performance in robotics. We thus focus on the solution
of basic problems in robotics while developing domain-appropriate machine-learning methods.
Starting from theoretically well-founded approaches to representing
the required control structures for task representation and
execution, we replace the analytically derived modules by more
flexible, learned ones.
This page presents an overview of our work on the following topics:
- Motor Skill Learning
- Imitation Learning
- Reinforcement Learning
- Visual and Tactile Object Exploration
- Robot Grasping and Manipulation
- Biomimetic Robotics, Human Motor Control and Brain-Robot Interfaces
Motor Skill Learning 
In the context of Motor Skill Learning, we are interested in a variety of topics that can be classified by three layers of abstraction:
A.) Learning to Execute: An essential problem in robotics is the accurate execution of desired movements using only low-gain controls such that the robot will accomplish the desired task while not harming human beings in its environment. Following a trajectory with little feedback requires the accurate prediction of the needed torques, which cannot be achieved using classical methods for sufficiently complex robots. However, learning such models is hard as the joint-space can never be fully explored and the learning algorithm has to cope with a never-ending data stream in real time. We have developed learning methods both for accomplishing tasks represented in operational space as well as in joint-space. For more information on learning to execute see:
-
- Nguyen Tuong, D.; Peters, J. (2011). Model Learning in Robotics: a Survey, Cognitive Processing, 12, 4.
-
- Nguyen Tuong, D.; Seeger, M.; Peters, J. (2009). Model Learning with Local Gaussian Process Regression, Advanced Robotics, 23, 15, pp.2015-2034.
-
- Peters, J.; Schaal, S. (2008). Learning to control in operational space, International Journal of Robotics Research (IJRR), 27, pp.197-212.
B.) Learning new Elementary Tasks: While learning to execute tasks is a component essential to a framework for motor skill learning, learning the actual task is of
even higher importance as discussed in here. We focus
on the learning of elementary tasks or movement primitives,
which are parameterized task representations based on nonlinear
differential equations with desired attractor properties. We mimic
how children learn new motor tasks using imitation learning for
initializing these movement primitives while employing reinforcement learning to subsequently improve the task performance.
We have learned tasks such as Ball-in-a-Cup or bouncing a ball
on a string using this approach.
In hitting and batting tasks, movement templates with a learned global shape need to be adapted during the execution so that the racket reaches a target position and velocity that will return the ball over to the other side of the net or court. This requires a reformulation of motor primitives to hitting primitives. A key motor skill for manipulating the environment is grasping, which is why one of our research goals is adapting machine learning algorithms to make them applicable in the robot grasping task domain. For grasping or hitting, several alternative motor primitives might be available. 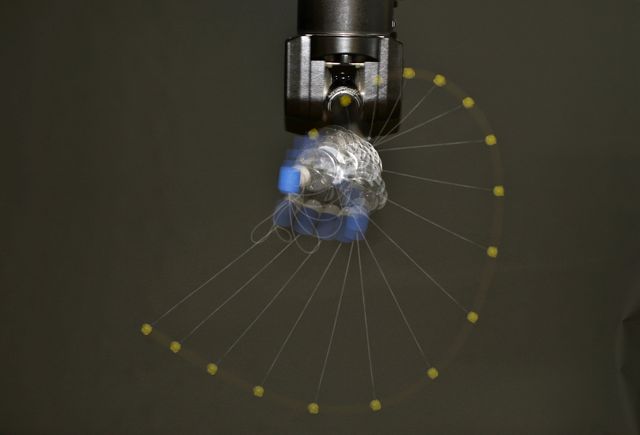
-
- Peters, J.; Schaal, S. (2008). Reinforcement learning of motor skills with policy gradients, Neural Networks, 21, 4, pp.682-97.
-
- Kober, J.; Peters, J. (2011). Policy Search for Motor Primitives in Robotics, Machine Learning (MLJ), 84, 1-2, pp.171-203.
C.) Learning to Compose Complex Tasks: Most complex tasks require several motor primitives to be executed in parallel or in sequence. The selection and composition of motor primitives requires a perceptuo-motor perspective, and is the necessary for learning complex tasks. An example of a complex tasks which requires motor primitive selection and hitting primitives is the task of learning to play ping-pong. Moving towards learning complex tasks requires the solution of a variety of hard problems. Among these are the decomposition of large tasks into movement primitives (MP), the acquisition and self-improvement of MPs, the determination of the number of MPs in a data set, the determination of the relevant task-space, perceptual context estimation and goal learning for MPs, as well as the composition of MPs for new complex tasks. These questions are tackled in order to make progress towards fast and general motor skill learning for robotics.
-
- Knaust, M.; Koert, D. (2021). Guided Robot Skill Learning: A User-Study on Learning Probabilistic Movement Primitives with Non-Experts, Proceedings of the International Conference on Humanoid Robots (HUMANOIDS).
- Peters, J.; Kober, J.; Muelling, K.; Kroemer, O.; Neumann, G. (2013). Towards Robot Skill Learning: From Simple Skills to Table Tennis, Proceedings of the European Conference on Machine Learning (ECML), Nectar Track.
- Peters, J.; Kober, J.; Muelling, K.; Nguyen-Tuong, D.; Kroemer, O. (2012). Robot Skill Learning, Proceedings of the European Conference on Artificial Intelligence (ECAI).
-
- Muelling, K.; Kober, J.; Kroemer, O.; Peters, J. (2013). Learning to Select and Generalize Striking Movements in Robot Table Tennis, International Journal of Robotics Research (IJRR), 32, 3, pp.263-279.
- Muelling, K.; Kober, J.; Kroemer, O.; Peters, J. (2012). Learning to Select and Generalize Striking Movements in Robot Table Tennis, Proceedings of the AAAI 2012 Fall Symposium on Robots that Learn Interactively from Human Teachers.
-
- Chiappa, S.; Kober, J.; Peters, J. (2009). Using Bayesian Dynamical Systems for Motion Template Libraries, Advances in Neural Information Processing Systems 22 (NIPS/NeurIPS), Cambridge, MA: MIT Press.
-
- Neumann, G.; Maass, W; Peters, J. (2009). Learning Complex Motions by Sequencing Simpler Motion Templates, Proceedings of the International Conference on Machine Learning (ICML2009).
-
- Kober, J.; Wilhelm, A.; Oztop, E.; Peters, J. (2012). Reinforcement Learning to Adjust Parametrized Motor Primitives to New Situations, Autonomous Robots (AURO), 33, 4, pp.361-379, Springer US.
Selected Related Research Topics: learning models for control, learning operational space control, reinforcement learning, learning motor primitives, learning complex tasks, learning to grasp, learning to play ping-pong, motor primitives for hitting, brain-robot interfaces
Imitation Learning
Research in robotics and artificial intelligence has lead to the development of complex robots such as humanoids and
androids.  In order to be meaningfully applied in human-inhabited environments, robots need to possess a variety of
physical abilities and skills. However, programming such skills is a labour- and time intensive task which requires a large
amount of expert knowledge. In particular, it often involves transforming intuitive concepts of motions and actions into
formal mathematical descriptions and algorithms.
In order to be meaningfully applied in human-inhabited environments, robots need to possess a variety of
physical abilities and skills. However, programming such skills is a labour- and time intensive task which requires a large
amount of expert knowledge. In particular, it often involves transforming intuitive concepts of motions and actions into
formal mathematical descriptions and algorithms.
To overcome such difficulties, we use imitation learning to teach robots new motor skills. A human demonstrator first provides one or several examples of the the skill. Information recorded through motion capture or physical interaction is used by the robot to automatically generate a controller that can replicate the seen movements. This is done using modern machine learning techniques. Imitation learning also allows robots to improve upon the observed behavior. This so called self-improvement of the task can help the robot to adapt the learned movement to the characteristics of its own body or the requirements of the current context. Hence, even if the examples presented by the human are not optimal, the robot can still use them to bootstrap its behavior.
At IAS, imitation learning has already been used to teach complex motor skills to various kinds of robots. This includes skills such as locomotion, grasping of novel objects , ping-pong, ball-in-the-cup and tetherball. New machine learning methods that reduce the time needed to acquire a motor skill are developed. The goal of this research is to have intelligent robots that can autonomously enlarge their repertoire of skills by observing or interacting with human teachers. If you want to read more, follow:
-
- Kober, J.; Peters, J. (2010). Imitation and Reinforcement Learning - Practical Algorithms for Motor Primitive Learning in Robotics, IEEE Robotics and Automation Magazine, 17, 2, pp.55-62.
-
- Ben Amor, H. (2010). Imitation Learning of Motor Skills for Synthetic Humanoids, Technische Universitaet Bergakademie Freiberg.
-
- Boularias, A.; Kober, J.; Peters, J. (2011). Relative Entropy Inverse Reinforcement Learning, Proceedings of Fourteenth International Conference on Artificial Intelligence and Statistics (AISTATS 2011).
Contact: Jan Peters, Heni Ben Amor, Abdeslam Boularias, Jens Kober, Katharina Muelling
Download: Flyer as PDF
Reinforcement Learning
Efficient reinforcement learning for continuous states and actions
is essential for robotics and control. We follow two approaches
depending on the dimensionality of the domain. For high-dimensional 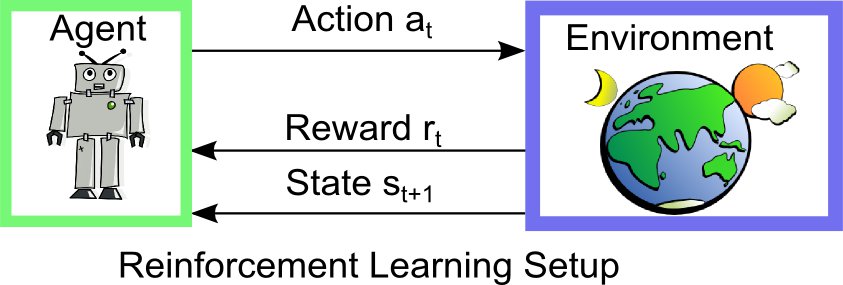 state and action spaces, it is often easier to directly learn
policies without estimating accurate system models. The resulting algorithms are parametric policy search algorithms inspired
by expectation-maximization methods and can be employed for
motor primitive learning. For lower-dimensional systems,
Bayesian approaches to control can be shown to be able to cope
with the optimization bias introduced by the model errors in
model-based reinforcement learning. As a result, these methods
can learn good policies at a rapid pace based on only little interaction of the system. Supervised learning is not always sufficient for motor learning problems, partly because often an expert teacher or idealized version of the behavior is not available. Because of that, one of our goals it the development reinforcement learning methods which scale into the dimensionality of humanoid robots and can generate actions for seven or more degrees of freedom.
state and action spaces, it is often easier to directly learn
policies without estimating accurate system models. The resulting algorithms are parametric policy search algorithms inspired
by expectation-maximization methods and can be employed for
motor primitive learning. For lower-dimensional systems,
Bayesian approaches to control can be shown to be able to cope
with the optimization bias introduced by the model errors in
model-based reinforcement learning. As a result, these methods
can learn good policies at a rapid pace based on only little interaction of the system. Supervised learning is not always sufficient for motor learning problems, partly because often an expert teacher or idealized version of the behavior is not available. Because of that, one of our goals it the development reinforcement learning methods which scale into the dimensionality of humanoid robots and can generate actions for seven or more degrees of freedom.
Our general goal in reinforcement learning is the development of methods which scale into the dimensionality of humanoid robots which is a tremendous challenge for reinforcement learning as a complete exploration of the underlying state-action spaces is impossible and few existing techniques scale into this domain. Therefore we rely upon a combination of both, watching a teacher and subsequent self-improvement. In more technical terms: first, a control policy is obtained by imitation and then improved using reinforcement learning.
Parametrized policies allow an efficient abstraction of the high-dimensional continuous action spaces which is often needed in robotics. We can directly optimize the parameters of the primitive by the use of policy search methods. 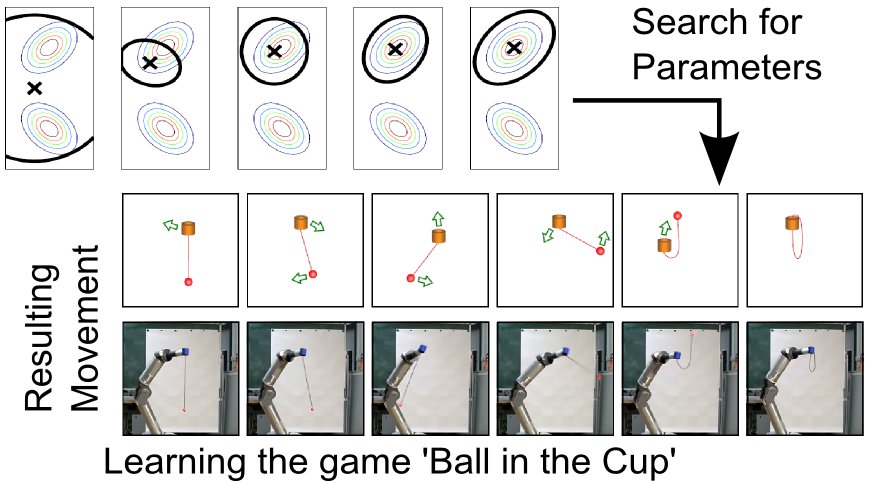 Members of IAS have developed a variety of novel algorithms for this context which have been applied for learning to play table tennis, the game 'Ball in the Cup' or darts.
Members of IAS have developed a variety of novel algorithms for this context which have been applied for learning to play table tennis, the game 'Ball in the Cup' or darts.
A.) Natural Actor-Critic (NAC): The NAC is currently considered the most efficient policy gradient method. It makes use of the fact, that a natural gradient usually beats a vanilla gradient. For more information read:
-
- Peters, J.; Schaal, S. (2008). Reinforcement learning of motor skills with policy gradients, Neural Networks, 21, 4, pp.682-97.
-
- Peters, J.; Schaal, S. (2008). Natural actor critic, Neurocomputing, 71, 7-9, pp.1180-1190.
B.) EM-like Reinforcement Learning: We formulated policy search as an inference problem. This has led to efficient algorithms like reward-weighted regression and PoWER. For more information read:
-
- Peters, J.;Schaal, S. (2007). Reinforcement learning by reward-weighted regression for operational space control, Proceedings of the International Conference on Machine Learning (ICML2007).
-
- Kober, J.; Peters, J. (2009). Policy Search for Motor Primitives in Robotics, Advances in Neural Information Processing Systems 22 (NIPS/NeurIPS), Cambridge, MA: MIT Press.
-
- Neumann, G.; Peters, J. (2009). Fitted Q-iteration by Advantage Weighted Regression, Advances in Neural Information Processing Systems 22 (NIPS/NeurIPS), Cambridge, MA: MIT Press.
-
- Neumann, G. (2011). Variational Inference for Policy Search in Changing Situations, Proceedings of the International Conference on Machine Learning (ICML 2011) .
C.) Relative Entropy Policy Search (REPS): The optimization in policy search can rapidly change the control policy which might lead to suboptimal solutions. REPS solves this problem by bounding the Relative Entropy between two subsequent policies. This allows the derivation of a whole range of new algorithms, including learning hierarchical policies. For more information read:
-
- Peters, J.; Muelling, K.; Altun, Y. (2010). Relative Entropy Policy Search, Proceedings of the Twenty-Fourth National Conference on Artificial Intelligence (AAAI), Physically Grounded AI Track.
-
- Daniel, C.; Neumann, G.; Kroemer, O.; Peters, J. (2016). Hierarchical Relative Entropy Policy Search, Journal of Machine Learning Research (JMLR), 17, pp.1-50.
- Daniel, C.; Neumann, G.; Peters, J. (2012). Hierarchical Relative Entropy Policy Search, Proceedings of the International Conference on Artificial Intelligence and Statistics (AISTATS 2012).
- Daniel, C. (2012). Hierarchical Relative Entropy Policy Search, Masters Thesis.
Contact: Jan Peters, Marc Deisenroth, Gerhard Neumann, Jens Kober, Christian Daniel, Abdeslam Boularias
Download: Flyer as PDF
Tactile and Visual Object Exploration
A robot needs to be aware of the properties of  objects to efficiently perform tasks with them.
Currently, most robots are provided with this
object information by a programmer. However,
autonomous robots working in service industries
and domestic settings will need to perform tasks
with novel objects. Hence, relying on predefined
object knowledge will not be an option.
objects to efficiently perform tasks with them.
Currently, most robots are provided with this
object information by a programmer. However,
autonomous robots working in service industries
and domestic settings will need to perform tasks
with novel objects. Hence, relying on predefined
object knowledge will not be an option.
Instead, robots will have to learn about objects by exploring their properties through physical interactions, such as pushing, stroking, and lifting. As random exploration is an inefficient approach, we develop methods for efficiently gathering information.
The fundamental knowledge learned about objects and primitive actions will later on form the basis for learning complex behaviors and predicting the properties of novel objects. By discovering accurate representations of objects, the robot will be able to plan and execute manipulations more precisely.
A) Learning Tactile Sensing using Vision: The textures of object surfaces can be observed both by visual inspection and by sliding a dynamic tactile sensor across the surface. The robot can combine these types of sensor readings to determine which components of the data contain information pertaining to the texture.
In particular, the robot can find the components that are maximally correlated between the two sensor modalities. Given the relevant data components, the robot can create a compact representation of object textures, which allows it to distinguish between surfaces more accurately.
-
- Kroemer, O.; Lampert, C.H.; Peters, J. (2011). Learning Dynamic Tactile Sensing with Robust Vision-based Training, IEEE Transactions on Robotics (T-Ro), 27, 3, pp.545-557.
B) Active Learning of Object Properties:
Learning about objects is not a passive  perceptual process: its embodiment allows a
robot to discover object properties by actively
changing its point of view and by interacting
with objects. At the same time, the robot
observes the effect of its actions and learns how
it can bring about desired effects.
perceptual process: its embodiment allows a
robot to discover object properties by actively
changing its point of view and by interacting
with objects. At the same time, the robot
observes the effect of its actions and learns how
it can bring about desired effects.
To learn efficiently, the robot should select the exploratory actions that yields the highest information gain out of all possible actions. By efficiently exploring its environment, a robot develops object knowledge grounded in its sensorimotor experience.
The developed object knowledge can be used to manipulate previously unknown objects in unstructured environments. For example, the robot could teach itself to perform tasks in domestic environments.
-
- van Hoof, H.; Kroemer, O.;Ben Amor, H.; Peters, J. (2012). Maximally Informative Interaction Learning for Scene Exploration, Proceedings of the International Conference on Robot Systems (IROS).
Contact: Jan Peters, Heni Ben Amor, Oliver Kroemer, Herke van Hoof
Download: Flyer as PDF
Robot Grasping and Manipulation
A key long-term goal of robotics is to create autonomous robots that can perform a wide range of tasks to help humans in daily life. One of the main requirements of such domestic and service robots is the ability to manipulate a wide range of objects in their surroundings.
Modern industrial robots usually only have to manipulate a single set of identical objects, using preprogrammed actions. However, future service robots will need to operate in unstructured environments and perform tasks with novel objects. These robots will therefore need to learn to optimize their actions to specific objects, as well as generalize their actions between objects.
A) Improving Grasps through Experience: The ability  to grasp objects is an important prerequisite for performing various manipulation tasks. Using trial-and-error, a robot can autonomously optimize its grasps of objects. In particular, the grasp selection process can be framed as a continuum-armed bandit reinforcement learning problem. Thus, the robot can actively balance executing grasps that are known to be good and exploring new grasps that may be better.
to grasp objects is an important prerequisite for performing various manipulation tasks. Using trial-and-error, a robot can autonomously optimize its grasps of objects. In particular, the grasp selection process can be framed as a continuum-armed bandit reinforcement learning problem. Thus, the robot can actively balance executing grasps that are known to be good and exploring new grasps that may be better.
-
- Kroemer, O.; Detry, R.; Piater, J.; Peters, J. (2010). Combining Active Learning and Reactive Control for Robot Grasping, Robotics and Autonomous Systems, 58, 9, pp.1105-1116.
-
- Boularias, A.; Kroemer, O.; Peters, J. (2011). Learning Robot Grasping from 3D Images with Markov Random Fields, IEEE/RSJ International Conference on Intelligent Robot Systems (IROS).
-
- Ben Amor, H.; Kroemer, O.; Hillenbrand, U.; Neumann, G.; Peters, J. (2012). Generalization of Human Grasping for Multi-Fingered Robot Hands, Proceedings of the International Conference on Robot Systems (IROS).
B) Affordance Learning: An object's affordances are the actions that the robot can perform using the object.  The affordances of basic objects, such as tools, are usually defined by their surface structures. By finding similar surface structures in different objects, the robot can transfer its knowledge of afforded actions between objects. In this manner, the robot can predict whether a novel object affords a specific action, as well as adapt the action to this object.
The affordances of basic objects, such as tools, are usually defined by their surface structures. By finding similar surface structures in different objects, the robot can transfer its knowledge of afforded actions between objects. In this manner, the robot can predict whether a novel object affords a specific action, as well as adapt the action to this object.
The robot can learn an initial action from a human demonstration. Adapting this action to new objects is achieved autonomously by the robot, using a trial-and-error learning approach.
-
- Piater, J.; Jodogne, S.; Detry, R.; Kraft, D.; Krueger, N.; Kroemer, O.; Peters, J. (2011). Learning Visual Representations for Perception-Action Systems, International Journal of Robotics Research (IJRR), 30, 3, pp.294-307.
-
- Kroemer, O.; Ugur, E.; Oztop, E. ; Peters, J. (2012). A Kernel-based Approach to Direct Action Perception, Proceedings of the International Conference on Robotics and Automation (ICRA).
Contact: Jan Peters, Heni Ben Amor, Abdeslam Boularias, Oliver Kroemer, Herke van Hoof
Download: Flyer as PDF
Biomimetic Robotics, Human Motor Control and Brain-Robot Interfaces
An different research goal focuses on human motion: using the tools that we develop for robot motor learning may be beneficial to understand human motor control as well as be used in brain-robot interfaces that learn to help stroke patients to rehabilitate. For more information on some of our work in this context see:
-
- Gomez Rodriguez, M.; Grosse-Wentrup, M.; Hill, J.; Schoelkopf, B.; Gharabaghi, A.; Peters, J. (2011). Towards Brain-Robot Interfaces for Stroke Rehabilitation, Proceedings of the International Conference on Rehabilitation Robotics (ICORR).
-
- Meyer, T.; Peters, J.;Broetz, D.; Zander, T.; Schoelkopf, B.; Soekadar, S.; Grosse-Wentrup, M. (2012). A Brain-Robot Interface for Studying Motor Learning after Stroke, Proceedings of the International Conference on Robot Systems (IROS).
-
- Gomez Rodriguez, M.; Peters, J.; Hill, J.; Schoelkopf, B.; Gharabaghi, A.; Grosse-Wentrup, M. (2011). Closing the Sensorimotor Loop: Haptic Feedback Helps Decoding of Motor Imagery, Journal of Neuroengineering, 8, 3.
-
- Muelling, K.; Kober, J.; Peters, J. (2011). A Biomimetic Approach to Robot Table Tennis, Adaptive Behavior Journal, 19, 5.