
Research Overview
Creating autonomous robots that can learn to assist humans in situations of daily life is a fascinating challenge for machine learning. While this aim has been a long-standing vision of artificial intelligence and the cognitive sciences, we have yet to achieve the first step of creating robots that can learn to accomplish many different tasks triggered by environmental context or higher-level instruction. The goal of our robot learning laboratory is the investigation of the ingredients for such a general approach to motor skill learning, to get closer towards human-like performance in robotics. We thus focus on the solution of basic problems in robotics while developing domain-appropriate machine-learning methods. Starting from theoretically well-founded approaches to representing the required control structures for task representation and execution, we replace the analytically derived modules by more flexible, learned ones. Our research builds on, extends and connects different disciplines, in particular the fields of Robotics and Control, Machine Learning, and Cognitive Science.
Robot Skill Learning 
Research in robotics and artificial intelligence has lead to the development of complex robots such as humanoids and androids. In order to be meaningfully applied in human-inhabited environments, robots need to possess a variety of physical abilities and skills. However, programming such skills is a labor- and time intensive task which requires a large amount of expert knowledge. In order to make robot programming amenable to non-experts we devise new methods for imitation learning and investigate new ways for representing robot movements.
Imitation Learning

To overcome such difficulties, we use imitation learning to teach robots new motor skills. A human demonstrator first provides one or several examples of the skill. Information recorded through motion capture or physical interaction is used by the robot to automatically generate a controller that can replicate the seen movements. This is done using modern machine learning techniques. Imitation learning also allows robots to improve the observed behavior. This so-called self-improvement of the task can help the robot to adapt the learned movement to the characteristics of its own body or the requirements of the current context. Hence, even if the examples presented by the human are not optimal, the robot can still use them to bootstrap its behavior.
At IAS, imitation learning has already been used to teach complex motor skills to various kinds of robots. This includes skills such as locomotion, grasping of novel objects , ping-pong, ball-in-the-cup and tetherball. New machine learning methods that reduce the time needed to acquire a motor skill are developed. The goal of this research is to have intelligent robots that can autonomously enlarge their repertoire of skills by observing or interacting with human teachers.
Key References
-
- Boularias, A.; Kober, J.; Peters, J. (2011). Relative Entropy Inverse Reinforcement Learning, Proceedings of Fourteenth International Conference on Artificial Intelligence and Statistics (AISTATS 2011).
-
- Arenz, O.; Abdulsamad, H.; Neumann, G. (2016). Optimal Control and Inverse Optimal Control by Distribution Matching, Proceedings of the International Conference on Intelligent Robots and Systems (IROS), IEEE.
-
- Ewerton, M.; Maeda, G.J.; Kollegger, G.; Wiemeyer, J.; Peters, J. (2016). Incremental Imitation Learning of Context-Dependent Motor Skills, Proceedings of the International Conference on Humanoid Robots (HUMANOIDS), pp.351--358.
Contact: Jan Peters, Gerhard Neumann, Rudolf Lioutikov, Oleg Arenz, Boris Belousov, Hany Abdulsamad, Marco Ewerton, Michael Lutter, Dorothea Koert, Joni Pajarinen
Download: Flyer as PDF
Movement Primitives
Movement Primitives are movement representations that can be combined to generate different or more complex behaviors. In general, they present generalization capabilities, such as changing the speed of execution, changing start position, goal position and via points.
Probabilistic Movement Primitives
We developed a novel movement primitive representation, capable for imitation learning. 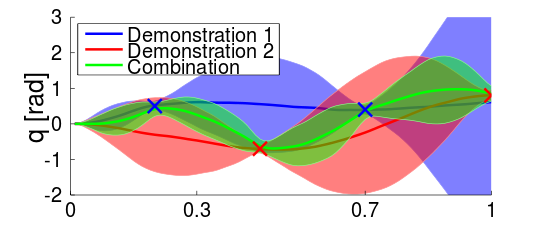 The new approach is called Probabilistic Movement Primitives (ProMPs) and allows for blending between motions, adapting to altered task variables, and co-activating multiple MPs in parallel. We based our approach on a probabilistic formulation of the movement primitive concept that maintains a distribution over trajectories. Our probabilistic approach allows for the derivation of new operations which are essential for implementing all aforementioned properties in one framework. In order to use such a trajectory distribution for robot movement control, we analytically derive a stochastic feedback controller which reproduces the given trajectory distribution. We have evaluated and compared our approach to existing methods on several simulated as well as real robot scenarios.
The new approach is called Probabilistic Movement Primitives (ProMPs) and allows for blending between motions, adapting to altered task variables, and co-activating multiple MPs in parallel. We based our approach on a probabilistic formulation of the movement primitive concept that maintains a distribution over trajectories. Our probabilistic approach allows for the derivation of new operations which are essential for implementing all aforementioned properties in one framework. In order to use such a trajectory distribution for robot movement control, we analytically derive a stochastic feedback controller which reproduces the given trajectory distribution. We have evaluated and compared our approach to existing methods on several simulated as well as real robot scenarios.
-
- Paraschos, A.; Daniel, C.; Peters, J.; Neumann, G (2013). Probabilistic Movement Primitives, Advances in Neural Information Processing Systems (NIPS / NeurIPS), MIT Press.
-
- Paraschos, A.; Neumann, G; Peters, J. (2013). A Probabilistic Approach to Robot Trajectory Generation, Proceedings of the International Conference on Humanoid Robots (HUMANOIDS).
-
- Ewerton, M.; Maeda, G.; Neumann, G.; Kisner, V.; Kollegger, G.; Wiemeyer, J.; Peters, J. (2016). Movement Primitives with Multiple Phase Parameters, Proceedings of the International Conference on Robotics and Automation (ICRA), pp.201--206.
-
- Kober, J.; Peters, J. (2010). Imitation and Reinforcement Learning - Practical Algorithms for Motor Primitive Learning in Robotics, IEEE Robotics and Automation Magazine, 17, 2, pp.55-62.
Learning to Execute
An essential problem in robotics is the accurate execution of desired movements using only low-gain control such that the robot will accomplish the desired task while not harming human beings in its environment. Following a trajectory with little feedback requires the accurate prediction of the needed torques, which cannot be achieved using classical methods for sufficiently complex robots. However, learning such models is hard as the joint-space can never be fully explored and the learning algorithm has to cope with a never-ending data stream in real time. We have developed learning methods both for accomplishing tasks represented in operational space as well as in joint-space. For more information on learning to execute see:
-
- Nguyen Tuong, D.; Peters, J. (2011). Model Learning in Robotics: a Survey, Cognitive Processing, 12, 4.
-
- Nguyen Tuong, D.; Seeger, M.; Peters, J. (2009). Model Learning with Local Gaussian Process Regression, Advanced Robotics, 23, 15, pp.2015-2034.
-
- Peters, J.; Schaal, S. (2008). Learning to control in operational space, International Journal of Robotics Research (IJRR), 27, pp.197-212.
Learning new Elementary Tasks
While learning to execute tasks is a component essential to a framework for motor skill learning, learning the actual task is of even higher importance as discussed in here. We focus on the learning of elementary tasks or movement primitives,
which are parameterized task representations based on nonlinear differential equations with desired attractor properties. We mimic how children learn new motor tasks using imitation learning for initializing these movement primitives while employing reinforcement learning to subsequently improve the task performance.
We have learned tasks such as Ball-in-a-Cup or bouncing a ball on a string using this approach.
In hitting and batting tasks, movement templates with a learned global shape need to be adapted during the execution so that the racket reaches a target position and velocity that will return the ball over to the other side of the net or court. This requires a reformulation of motor primitives to hitting primitives. A key motor skill for manipulating the environment is grasping, which is why one of our research goals is adapting machine learning algorithms to make them applicable in the robot grasping task domain. For grasping or hitting, several alternative motor primitives might be available. 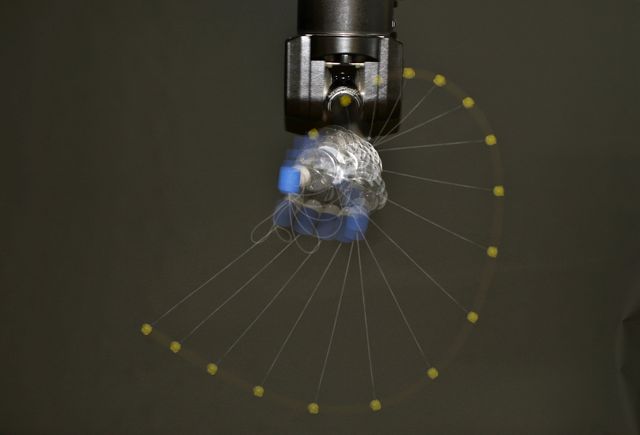
-
- Peters, J.; Schaal, S. (2008). Reinforcement learning of motor skills with policy gradients, Neural Networks, 21, 4, pp.682-97.
-
- Kober, J.; Peters, J. (2011). Policy Search for Motor Primitives in Robotics, Machine Learning (MLJ), 84, 1-2, pp.171-203.
Learning to Compose Complex Tasks
Most complex tasks require several motor primitives to be executed in parallel or in sequence. The selection and composition of motor primitives requires a perceptuo-motor perspective and is necessary for learning complex tasks. An example of a complex task which requires motor primitive selection and hitting primitives is the task of learning to play ping-pong. Moving towards learning complex tasks requires the solution of a variety of hard problems. Among these are the decomposition of large tasks into movement primitives (MP), the acquisition and self-improvement of MPs, the determination of the number of MPs in a data set, the determination of the relevant task-space, perceptual context estimation and goal learning for MPs, as well as the composition of MPs for new complex tasks. These questions are tackled in order to make progress towards fast and general motor skill learning for robotics.
-
- Peters, J.; Kober, J.; Muelling, K.; Kroemer, O.; Neumann, G. (2013). Towards Robot Skill Learning: From Simple Skills to Table Tennis, Proceedings of the European Conference on Machine Learning (ECML), Nectar Track.
-
- Muelling, K.; Kober, J.; Kroemer, O.; Peters, J. (2013). Learning to Select and Generalize Striking Movements in Robot Table Tennis, International Journal of Robotics Research (IJRR), 32, 3, pp.263-279.
-
- Lioutikov, R.; Neumann, G.; Maeda, G.J.; Peters, J. (2015). Probabilistic Segmentation Applied to an Assembly Task, Proceedings of the International Conference on Humanoid Robots (HUMANOIDS).
-
- Kober, J.; Wilhelm, A.; Oztop, E.; Peters, J. (2012). Reinforcement Learning to Adjust Parametrized Motor Primitives to New Situations, Autonomous Robots (AURO), 33, 4, pp.361-379, Springer US.
Selected Related Research Topics: learning models for control, learning operational space control, reinforcement learning, learning motor primitives, learning complex tasks, learning to grasp, learning to play ping-pong, motor primitives for hitting, brain-robot interfaces
Machine Learning
We use machine learning in order to enable robots to learn complex skills from data. Most importantly, we focus on reinforcement learning in order to directly learn the desired behavior from experience. However, we also investigate other sub-fields of machine learning in order to meet the particular requirements for robot skill learning. It is, for example, usually very costly to collect data on a robot and it is therefore important to make good use of limited amounts of data. This scarcity of data requires high sample efficiency not only for reinforcement learning, but often also during optimization or probabilistic inference.
Reinforcement Learning
Supervised learning is not always sufficient for motor learning problems, partly because often an expert teacher or idealized version of the behavior is not available. Because of that, one of our goals is the development reinforcement learning methods which scale into the dimensionality of humanoid robots and can generate actions for seven or more degrees of freedom.
Efficient reinforcement learning for continuous states and actions is essential for robotics and control. We follow two approaches depending on the dimensionality of the domain. For high-dimensional 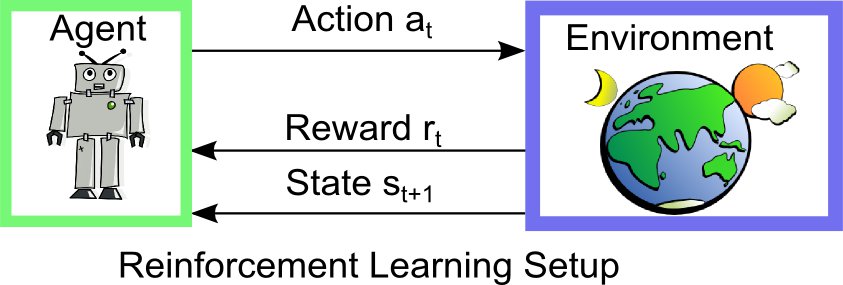 state and action spaces, it is often easier to directly learn policies without estimating accurate system models. The resulting algorithms are parametric policy search algorithms inspired
by expectation-maximization methods or information-theoretic policy updates and can be employed for
motor primitive learning.
Information-theoretic policy updates seem to be particularly suited for the high-dimensional problems that occur in robotics as
the update rules result in a smooth and robust policy update that always `stays close to the data'.
If we can learn a model of the robot and its environment, we can employ model-based reinforcement learning to drastically improve the sampling efficiency of policy search algorithms.
As a result, these methods can learn good policies at a rapid pace based on only little interaction of the system.
state and action spaces, it is often easier to directly learn policies without estimating accurate system models. The resulting algorithms are parametric policy search algorithms inspired
by expectation-maximization methods or information-theoretic policy updates and can be employed for
motor primitive learning.
Information-theoretic policy updates seem to be particularly suited for the high-dimensional problems that occur in robotics as
the update rules result in a smooth and robust policy update that always `stays close to the data'.
If we can learn a model of the robot and its environment, we can employ model-based reinforcement learning to drastically improve the sampling efficiency of policy search algorithms.
As a result, these methods can learn good policies at a rapid pace based on only little interaction of the system.
Our general goal in reinforcement learning is the development of methods which scale into the dimensionality of humanoid robots. Such high dimensionalities is a tremendous challenge for reinforcement learning as a complete exploration of the underlying state-action spaces is impossible and few existing techniques scale into this domain. Therefore we rely upon a combination of both, watching a teacher and subsequent self-improvement. In more technical terms: first, a control policy is obtained by imitation and then improved using reinforcement learning.
Parametrized policies allow an efficient abstraction of the high-dimensional continuous action spaces which is often needed in robotics. We can directly optimize the parameters of the primitive by the use of policy search methods. 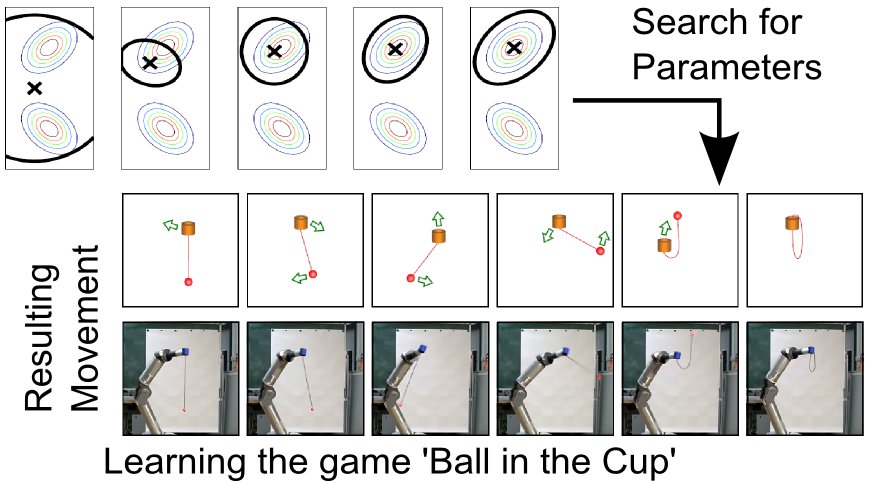 Members of IAS have developed a variety of novel algorithms for this context which have been applied for learning to play table tennis, tetherball, the game 'ball in the cup' and darts.
Members of IAS have developed a variety of novel algorithms for this context which have been applied for learning to play table tennis, tetherball, the game 'ball in the cup' and darts.
Natural Actor-Critic (NAC)
The NAC is currently considered the most efficient policy gradient method. It makes use of the fact, that a natural gradient usually beats a vanilla gradient. For more information read:
-
- Peters, J.; Schaal, S. (2008). Reinforcement learning of motor skills with policy gradients, Neural Networks, 21, 4, pp.682-97.
-
- Peters, J.; Schaal, S. (2007). Applying the episodic natural actor-critic architecture to motor primitive learning, Proceedings of the 2007 European Symposium on Artificial Neural Networks (ESANN).
- Peters, J.;Vijayakumar, S.;Schaal, S. (2005). Natural Actor-Critic, Proceedings of the 16th European Conference on Machine Learning (ECML 2005).
EM-like Reinforcement Learning
We formulated policy search as an inference problem. This has led to efficient algorithms like reward-weighted regression and PoWER. For more information read:
-
- Peters, J.;Schaal, S. (2007). Reinforcement learning by reward-weighted regression for operational space control, Proceedings of the International Conference on Machine Learning (ICML2007).
-
- Kober, J.; Peters, J. (2009). Policy Search for Motor Primitives in Robotics, Advances in Neural Information Processing Systems 22 (NIPS/NeurIPS), Cambridge, MA: MIT Press.
-
- Neumann, G.; Peters, J. (2009). Fitted Q-iteration by Advantage Weighted Regression, Advances in Neural Information Processing Systems 22 (NIPS/NeurIPS), Cambridge, MA: MIT Press.
-
- Neumann, G. (2011). Variational Inference for Policy Search in Changing Situations, Proceedings of the International Conference on Machine Learning (ICML 2011) .
Information-theoretic Policy Search
The optimization in policy search can rapidly change the control policy, which might lead to jumps in the policy as well as in the resulting trajectory distribution. While this behavior might already be dangerous for a real robot, it might also lead to premature convergence to suboptimal solutions or even oscillations. Information-theoretic policy search solves this problem by bounding the Relative Entropy between two subsequent policies. Hence, the new policy always tries to stay close to the `data' that has been generated by the old policy, while maximizing the reward locally. Such policy updates are mathematically sound and allow the derivation of a whole range of new algorithms, including contextual policy search and learning hierarchical policies. For more information read:
-
- Peters, J.; Muelling, K.; Altun, Y. (2010). Relative Entropy Policy Search, Proceedings of the Twenty-Fourth National Conference on Artificial Intelligence (AAAI), Physically Grounded AI Track.
-
- Daniel, C.; Neumann, G.; Peters, J. (2012). Hierarchical Relative Entropy Policy Search, Proceedings of the International Conference on Artificial Intelligence and Statistics (AISTATS 2012).
-
- Kupcsik, A.G.; Deisenroth, M.P.; Peters, J.; Ai Poh, L.; Vadakkepat, V.; Neumann, G. (2017). Model-based Contextual Policy Search for Data-Efficient Generalization of Robot Skills, Artificial Intelligence, 247, pp.415-439.
-
- van Hoof, H.; Peters, J.; Neumann, G. (2015). Learning of Non-Parametric Control Policies with High-Dimensional State Features, Proceedings of the International Conference on Artificial Intelligence and Statistics (AISTATS).
-
- Parisi, S.; Abdulsamad, H.; Paraschos, A.; Daniel, C.; Peters, J. (2015). Reinforcement Learning vs Human Programming in Tetherball Robot Games, Proceedings of the IEEE/RSJ Conference on Intelligent Robots and Systems (IROS).
-
- Akrour, R.; Abdolmaleki, A.; Abdulsamad, H.; Neumann, G. (2016). Model-Free Trajectory Optimization for Reinforcement Learning, Proceedings of the International Conference on Machine Learning (ICML).
-
- Tangkaratt, V.; van Hoof, H.; Parisi, S.; Neumann, G.; Peters, J.; Sugiyama, M. (2017). Policy Search with High-Dimensional Context Variables, Proceedings of the AAAI Conference on Artificial Intelligence (AAAI).
-
- End, F.; Akrour, R.; Peters, J.; Neumann, G. (2017). Layered Direct Policy Search for Learning Hierarchical Skills, Proceedings of the International Conference on Robotics and Automation (ICRA).
-
- Abdulsamad, H.; Arenz, O.; Peters, J.; Neumann, G. (2017). State-Regularized Policy Search for Linearized Dynamical Systems, Proceedings of the International Conference on Automated Planning and Scheduling (ICAPS).
For an overview of these approaches, please also consult the following survey papers from IAS members:
-
- Deisenroth, M. P.; Neumann, G.; Peters, J. (2013). A Survey on Policy Search for Robotics, Foundations and Trends in Robotics, 21, pp.388-403.
-
- Kober, J.; Bagnell, D.; Peters, J. (2013). Reinforcement Learning in Robotics: A Survey, International Journal of Robotics Research (IJRR), 32, 11, pp.1238-1274.
Contact: Jan Peters, Gerhard Neumann, Simone Parisi, Joni Pajarinen, Riad Akrour, Boris Belousov, Hany Abdulsamad, Gregor Gebhardt, Samuele Tosatto, Michael Lutter
Download: Flyer as PDF
Reinforcement Learning from Physics Simulations

Learning new control policies on real robot systems is generically time-intensive and may lead to catastrophic robot failures. Therefore, simulation-based policy search appears to be an appealing alternative. Unfortunately, running policy search algorithms on a slightly faulty simulator can easily lead to the exploitation of modeling errors, such that the resulting behavior can potentially damage the robot. For this reason, much work in robot reinforcement learning has focused on model-free methods that learn on real-world systems. This lack of using simulators, unfortunately, results in an extensive need for robot time during training and imposes severe constraints on the applicable methods.
The aim of our research is to fundamentally speed-up robot learning by making the control policies resulting from the physics simulations directly deployable in the real world. To do so, we explore how policy optimization can be made more robust by perturbing the simulator’s parameters and training from ensembles of models instead of just one nominal model.
Contact: Fabio Muratore, Jan Peters
Multi-Objective Reinforcement Learning
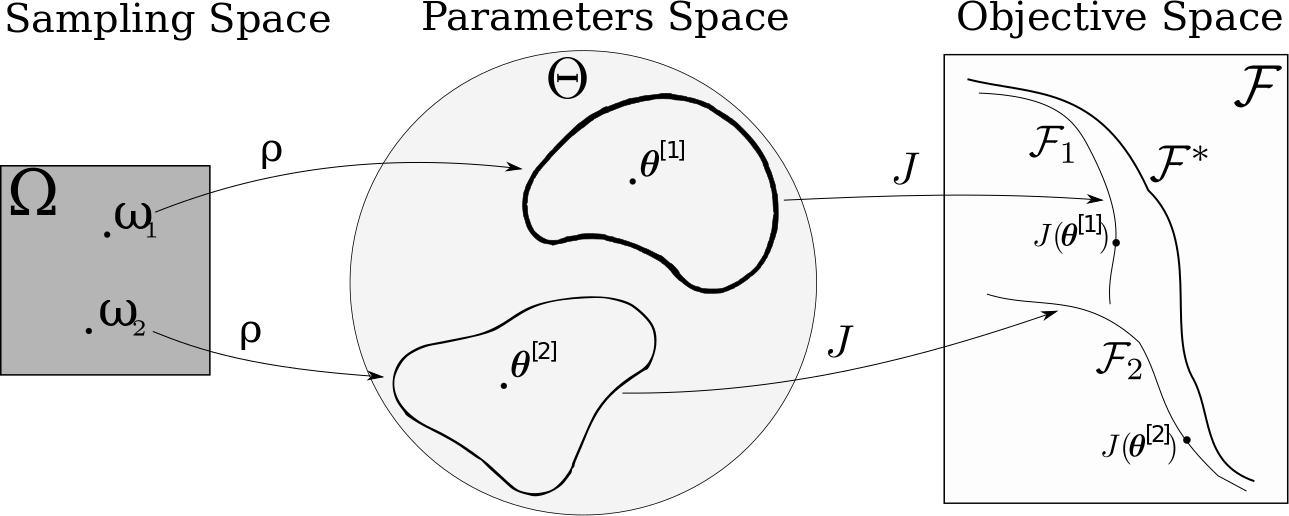
Many real-world applications are characterized by multiple conflicting objectives. In such problems optimality is replaced by Pareto optimality and the goal is to find the Pareto frontier, a set of solutions representing different compromises among the objectives. Despite recent advances in multi-objective optimization, achieving an accurate representation of the Pareto frontier is still an important challenge.
We formulate the problem of approximating Pareto frontiers as MOMDPs and solve it with a manifold-based approach. We combine episodic exploration strategies and importance sampling to efficiently learn a manifold in the policy parameter space such that its image in the objective space accurately approximates the Pareto frontier.
-
- Parisi, S.; Pirotta, M.; Peters, J. (2017). Manifold-based Multi-objective Policy Search with Sample Reuse, Neurocomputing, 263, pp.3-14.
Intrinsically Motivated Reinforcement Learning
Intrinsic motivation defines a set of objectives the robot can pursue even in the absence of a task related reward. We are especially interested in combining intrinsic motivation and task-specific objectives. For instance, a robot can decide to maximize the entropy of its sensory-motor stream, resulting in an exploratory behavior. When combined with a task reward, this can ensure that exploration of diverse behaviors is restricted to the area of interest of the task.
Learning a diverse set of good performing behaviors can have several advantages. In an adversarial setting such as robot table tennis, diversity of behaviors renders the robot harder to predict and hence harder to counter for the opponent. In a collaborative task with a human, an emphasis on diversity gives the human more opportunity to guide the robot and to avoid the latter to be stuck in local optima.
-
- Gabriel, A.; Akrour, R.; Peters, J.; Neumann, G. (2017). Empowered Skills, Proceedings of the International Conference on Robotics and Automation (ICRA).
Contact: Simone Parisi, Riad Akrour, Svenja Stark, Michael Lutter, Jan Peters
Variational Inference
Many machine learning techniques that we use for robot skill learning are based on probabilistic models that are often complex and thus not amenable for exact statistical inference. Hence, we often need to rely on approximate inference, e.g. by using Monte Carlo estimates. However, standard techniques for approximate inference, such as Markov-chain Monte Carlo, may not provide sufficient sample efficiency for robot applications. By learning a tractable approximation of the complex probabilistic model Variational Inference frames statistical inference as an optimization problem and allows us to make better use of the available data.
Variational Inference by Policy Search (VIPS)
Interestingly, the problem of learning tractable approximations of probability distributions is very similar to the problem of Reinforcement Learning. This connection even goes so far that some Policy Search methods essentially solve the same optimization problem as some Variational Inference methods. Building on our expertise in Reinforcement Learning, we devised a novel method for Variational Inference that is capable of learning accurate Gaussian Mixture Model approximations of complex probability distributions. Our method is based on a lower bound on the objective function that enables us to decompose the optimization problem into simpler sub-problem while an Expectation-Maximization procedure ensures that we converge to an optimum of the true objective. We leverage insights from Reinforcement Learning by establishing information-theoretic trust region while optimizing the sub-problems. These trust-regions are crucial for exploration and stability, enabling us to perform approximate inference with similar quality to Markov-chain Monte Carlo while requiring several orders of magnitudes less function evaluations.
-
- Arenz, O.; Zhong, M.; Neumann, G. (2018). Efficient Gradient-Free Variational Inference using Policy Search, in: Dy, Jennifer and Krause, Andreas (eds.), Proceedings of the International Conference on Machine Learning (ICML), 80, pp.234--243, PMLR.
Bayesian Optimization
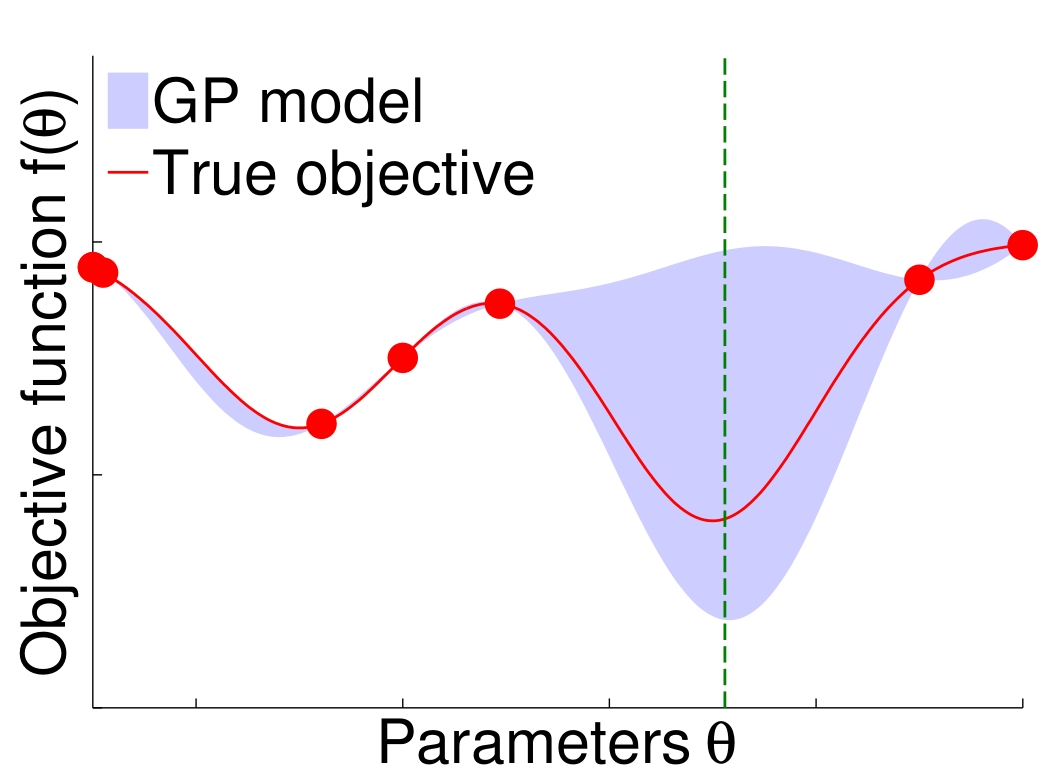
Optimizing parameters in robotics is a necessary but often hard task. The challenges arise from the presence of multiple local minima, noise in the measurements, lack of analytical gradients and the limited number of experiments possible on a real robot. Hence, typical approaches such as grid search, random search, gradient descent and genetic algorithms often perform poorly.
Bayesian optimization is designed to naturally deal with these challenges of optimization in robotics. Thanks to the use of a response surface model, Bayesian optimization drastically reduce the number of experiments needed. Hence, it can be successfully employed in a real system where other approaches would fail.
-
- Calandra, R.; Gopalan, N.; Seyfarth, A.; Peters, J.; Deisenroth, M.P. (2014). Bayesian Gait Optimization for Bipedal Locomotion, Proceedings of the 2014 Learning and Intelligent Optimization Conference (LION8).
-
- Calandra, R.; Seyfarth, A.; Peters, J.; Deisenroth, M.P. (2014). An Experimental Comparison of Bayesian Optimization for Bipedal Locomotion, Proceedings of 2014 IEEE International Conference on Robotics and Automation (ICRA).
Local Bayesian Optimization
The global nature of classical Bayesian optimization algorithms makes them ill-suited for high dimensional robotic tasks such as tuning a movement primitive's forcing function. Not only can the search for a global optimizer be sample inefficient, but evaluating parameters far from a known safe solution (such as provided by a human teacher) can be dangerous for the robot. For this purpose, we propose to retain the key principles of Bayesian optimization (i.e. a probabilistic modeling of the response surface and the use thereof in resolving the exploration-exploitation dilemma) and apply them in a local context. The resulting local Bayesian optimization algorithm is both sample efficient and safe by restraining the drift to initial human data.
-
- Akrour, R.; Sorokin, D.; Peters, J.; Neumann, G. (2017). Local Bayesian Optimization of Motor Skills, Proceedings of the International Conference on Machine Learning (ICML).
Contact: Riad Akrour, Jan Peters
Robotics and Control
In order to ensure the practicability of our devised methods for learning robot control it is inevitable to evaluate them on real systems and to compare them against more traditional engineered solutions. For this purpose, we regularly make use of our robotic laboratory that includes a variety of advanced robots. For safe human-robot interactions we operate several compliant robot platforms including two bimanual manipulation platforms, based on two Kuka LBR 4 and two Kuka IIWA R820 respectively, as well as a tetherball setup based on two BioRob robotic arms. For tasks that require fast and precise movements (such as table tennis and ball catching) we can use our Barrett WAM. Furthermore, we have several robotic hands for dexterous manipulation, mobile platforms (including the humanoid iCup) for locomotion and one hundred kilobots for swarm robotics.
Robot Grasping and Manipulation
A key long-term goal of robotics is to create autonomous robots that can perform a wide range of tasks to help humans in daily life. One of the main requirements of such domestic and service robots is the ability to manipulate a wide range of objects in their surroundings.
Modern industrial robots usually only have to manipulate a single set of identical objects, using preprogrammed actions. However, future service robots will need to operate in unstructured environments and perform tasks with novel objects. These robots will, therefore, need to learn to optimize their actions to specific objects, as well as generalize their actions between objects.
Improving Grasps through Experience
The ability  to grasp objects is an important prerequisite for performing various manipulation tasks. Using trial-and-error, a robot can autonomously optimize its grasps of objects. In particular, the grasp selection process can be framed as a continuum-armed bandit reinforcement learning problem. Thus, the robot can actively balance executing grasps that are known to be good and exploring new grasps that may be better.
to grasp objects is an important prerequisite for performing various manipulation tasks. Using trial-and-error, a robot can autonomously optimize its grasps of objects. In particular, the grasp selection process can be framed as a continuum-armed bandit reinforcement learning problem. Thus, the robot can actively balance executing grasps that are known to be good and exploring new grasps that may be better.
-
- Kroemer, O.; Detry, R.; Piater, J.; Peters, J. (2010). Combining Active Learning and Reactive Control for Robot Grasping, Robotics and Autonomous Systems, 58, 9, pp.1105-1116.
-
- Boularias, A.; Kroemer, O.; Peters, J. (2011). Learning Robot Grasping from 3D Images with Markov Random Fields, IEEE/RSJ International Conference on Intelligent Robot Systems (IROS).
-
- Ben Amor, H.; Kroemer, O.; Hillenbrand, U.; Neumann, G.; Peters, J. (2012). Generalization of Human Grasping for Multi-Fingered Robot Hands, Proceedings of the International Conference on Robot Systems (IROS).
Affordance Learning
An object's affordances are the actions that the robot can perform using the object.  The affordances of basic objects, such as tools, are usually defined by their surface structures. By finding similar surface structures in different objects, the robot can transfer its knowledge of afforded actions between objects. In this manner, the robot can predict whether a novel object affords a specific action, as well as adapt the action to this object.
The affordances of basic objects, such as tools, are usually defined by their surface structures. By finding similar surface structures in different objects, the robot can transfer its knowledge of afforded actions between objects. In this manner, the robot can predict whether a novel object affords a specific action, as well as adapt the action to this object.
The robot can learn an initial action from a human demonstration. Adapting this action to new objects is achieved autonomously by the robot, using a trial-and-error learning approach.
-
- Piater, J.; Jodogne, S.; Detry, R.; Kraft, D.; Krueger, N.; Kroemer, O.; Peters, J. (2011). Learning Visual Representations for Perception-Action Systems, International Journal of Robotics Research (IJRR), 30, 3, pp.294-307.
-
- Kroemer, O.; Ugur, E.; Oztop, E. ; Peters, J. (2012). A Kernel-based Approach to Direct Action Perception, Proceedings of the International Conference on Robotics and Automation (ICRA).
Multi-Phase Manipulations
Manipulation tasks can be decomposed into phases, wherein the robot's actions have distinct effects depending on the current phase. In order to perform a task, the robot will first need to reach a phase that affords the desired manipulation, which may require transitioning through other phases first. The phases thus define a sequence of subtasks for the robot to complete in order to manipulate different parts of the environment.
Our research has focused on developing methods for learning the phase structure of tasks, as well as learning manipulation skills for transitioning between the phases. The robot first learns the conditions for transitioning between phases and then optimizes its motor skills accordingly. In order to learn versatile manipulation skills, we have also investigated representations for generalizing phase transitions between different objects. As part of our research, the Darias robot has learned the phases of a variety of tasks, including stacking objects, pouring, two-handed grasping, and turning a pepper mill.
-
- Kroemer, O.; Daniel, C.; Neumann, G; van Hoof, H.; Peters, J. (2015). Towards Learning Hierarchical Skills for Multi-Phase Manipulation Tasks, Proceedings of the International Conference on Robotics and Automation (ICRA).
-
- Kroemer, O.; van Hoof, H.; Neumann, G.; Peters, J. (2014). Learning to Predict Phases of Manipulation Tasks as Hidden States, Proceedings of 2014 IEEE International Conference on Robotics and Automation (ICRA).
-
- Kroemer, O.; Peters, J. (2014). Predicting Object Interactions from Contact Distributions, Proceedings of the IEEE/RSJ Conference on Intelligent Robots and Systems (IROS).
-
- Brandl, S.; Kroemer, O.; Peters, J. (2014). Generalizing Pouring Actions Between Objects using Warped Parameters, Proceedings of the International Conference on Humanoid Robots (HUMANOIDS).
Contact: Jan Peters, Joni Pajarinen, Oleg Arenz
Download: Flyer as PDF
Tactile Sensing for Manipulation

Many current robots lack fine manipulation skills. A major reason for this is that most industrial robotic arm-hand systems do not receive sufficient feedback about the contact with the object. Neuroscience has shown that such feedback from tactile sensors is a critical component in the human ability to perform such tasks. Therefore, we aim to equip our robots with tactile sensors and use the sensor feedback for robot control. Research issues include how to interpret the signals from the sensors (that are often noisy and high-dimensional) and how to include such signals in a robot control loop. Among others, we aim to address such issues by using supervised, unsupervised, and reinforcement learning techniques.

-
- Veiga, F.F.; van Hoof, H.; Peters, J.; Hermans, T. (2015). Stabilizing Novel Objects by Learning to Predict Tactile Slip, Proceedings of the IEEE/RSJ Conference on Intelligent Robots and Systems (IROS).
-
- van Hoof, H.; Hermans, T.; Neumann, G.; Peters, J. (2015). Learning Robot In-Hand Manipulation with Tactile Features, Proceedings of the International Conference on Humanoid Robots (HUMANOIDS).
Contact: Filipe Veiga, Hany Abdulsamad, Daniel Tanneberg, Elmar Rückert, Jan Peters
Reinforcement Learning for Robot Manipulation
Machine learning and artificial intelligence have made important and substantial progress in recent years. By now, they are reaching large-scale applications in industrial environments. Such machine learning methods increasingly enable unforeseen development of new applications of technical systems and robots. Future robots will better recognize and understand their surrounding environment. Perception, however, is just the first step as the robot must derive meaningful actions from such perception. For complex tasks, it will not be possible to manually program all the handling rules which are required for the robot to succeed. This problem is particularly severe when the robot directly interacts with humans. For such tasks, learning robots are a promising alternative. The robot receives feedback from human beings in its environment and performance, e.g., in form of grades rating its behavior as positive or negative. The robot should subsequently adapt its behavior accordingly. Methods for learning through interaction are best addressed in the framework of ``Reinforcement Learning,'' a particularly hot sub-field of machine learning. Instead of being manually programmed to carry out the same task millions of times, future robots would be enabled to adapt to hundreds of different tasks autonomously and could become useful for small series production. The proposed research will develop reinforcement learning methods for more complex robot activities enabling as well as interaction with humans.
Contact: Samuele Tosatto, Rudolf Lioutikov, Joni Pajarinen, Jan Peters
Human-Robot Interaction
Due to the inherent stochasticity and diversity of human behavior, robots need learning and adaptation capabilities to successfully interact with humans in various scenarios. We have developed Machine Learning algorithms that enable robots to learn interactions from demonstrations. Those algorithms cope with the variability in space and time that is inherent in human behavior. Moreover, our group has investigated how robots can support the practice and execution of movements by humans. Applications of our methods have been demonstrated in assembly tasks involving humans and robots working in partnership, in scenarios where the human tries to learn a new motor skill such as writing characters, in teleoperation scenarios with shared autonomy between the human and the robot, among other situations.
Bidirectional Motor Skill Learning

The overlap between the workspaces of humans and robots has been increasing in the last decades. Situations in which people interact with robots are becoming more frequent. Such situations pose a number of research questions, such as:
- How can humans and robots learn the execution of movements together or from each other?
- What is the best way to combine the advantages of humans and robots?
Our research aims at determining efficient and effective interaction configurations in order to allow humans and robots to acquire new movements or improve their performance at tasks involving their sensorial and motor capabilities.
The search for configurations that allow humans and robots to jointly learn movements may result in a large number of applications: industrial robots may be retrained through the physical interaction with humans, instead of through the rewriting of lines of code; new devices and training programs for the rehabilitation of motor-impaired patients may be designed.
-
- Ewerton, M.; Rother, D.; Weimar, J.; Kollegger, G.; Wiemeyer, J.; Peters, J.; Maeda, G. (2018). Assisting Movement Training and Execution with Visual and Haptic Feedback, Frontiers in Neurorobotics.
-
-
- Ewerton, M.; Maeda, G.; Neumann, G.; Kisner, V.; Kollegger, G.; Wiemeyer, J.; Peters, J. (2016). Movement Primitives with Multiple Phase Parameters, Proceedings of the International Conference on Robotics and Automation (ICRA), pp.201--206.
Contact: Marco Ewerton, Jan Peters
Semi-Autonomous Assistive Robots and Interaction Learning

Semi-autonomous robots are robots that physically interact with a human partner in order to achieve a task in a collaborative manner. Fundamental research in semi-autonomous robotics has potential applications in a variety of scenarios where humans need assistance: assembly of products in factories, the aid of the elderly at home, control of actuated prosthetics, shared control in repetitive teleoperated processes.
Research for semi-autonomous robots needs to go beyond the usual sense-plan-act paradigm to account for the interaction with humans. Sensing and perception must involve the observation and interpretation of the human movement. Planning has to take into account the inferred human intent and, from a possibly limited repertoire of robot skills, search for an appropriate combination of actions. Acting for collaboration requires algorithms that model and predict human trajectories and generate safe and appropriate commands for both human and robot.
One of the challenges that we are currently addressing is related to the fact that humans usually execute a variety of unforeseen tasks; hence pre-programming a robot for all possible tasks is infeasible. We approach this problem by investigating new algorithms that allow a robot: (1) to learn and maintain a dynamic repertoire of skills and to assess its own ability to assist the human in accomplishing a given task, and (2) to make requests for human demonstration in order to acquire a new skill via imitation and reinforcement learning.
We also investigate ways to model collaborative interaction. Such a model is used to predict the intention and movement of the human while simultaneously generating collaborative control actions for the robot. Our current approach leverages on probabilistic tools for the realization of interaction primitives. Basically, a prior model of the interaction is encoded as a joint distribution of the human and robot movements, from which a posterior distribution of the interaction can be inferred by observing only the human.
We validate and demonstrate our algorithms using real robotic systems which also involves the milestones of the 3rd Hand Project (visit the website here, download the brochure here) as one of our driving applications. You can watch our latest results in here.
-
- Maeda, G.; Neumann, G.; Ewerton, M.; Lioutikov, R.; Kroemer, O.; Peters, J. (2017). Probabilistic Movement Primitives for Coordination of Multiple Human-Robot Collaborative Tasks, Autonomous Robots (AURO), 41, 3, pp.593-612.
-
- Maeda, G.; Ewerton, M.; Neumann, G.; Lioutikov, R.; Peters, J. (2017). Phase Estimation for Fast Action Recognition and Trajectory Generation in Human-Robot Collaboration, International Journal of Robotics Research (IJRR), 36, 13-14, pp.1579-1594.
-
- Ewerton, M.; Neumann, G.; Lioutikov, R.; Ben Amor, H.; Peters, J.; Maeda, G. (2015). Learning Multiple Collaborative Tasks with a Mixture of Interaction Primitives, Proceedings of the International Conference on Robotics and Automation (ICRA), pp.1535--1542.
Contacts: Marco Ewerton, Rudolf Lioutikov, Jan Peters
Whole Body Movement and Robot Locomotion


Dealing with whole body movement of humanoid robot is a highly challenging domain involving various different problems ranging from stabilizing behaviors (e.g., balancing, support oneself against objects) over static motions (e.g., getting up from a chair, push-ups) up to locomotion (e.g., walking, running). As of now, no robot exhibits the same dexterity, efficiency, speed and robustness as a human due to the difficulty of controlling and planning with a high number of degrees of freedom as well as due to the complexity of modeling and estimating physical contacts.
We aim to develop new approaches to improve the current state-of-the-art for whole body movement of humanoid robots in general, and, especially, for robot locomotion.
-
- Calandra, R.; Ivaldi, S.; Deisenroth, M.;Rueckert, E.; Peters, J. (2015). Learning Inverse Dynamics Models with Contacts, Proceedings of the International Conference on Robotics and Automation (ICRA).
-
- Calandra, R.; Gopalan, N.; Seyfarth, A.; Peters, J.; Deisenroth, M.P. (2014). Bayesian Gait Optimization for Bipedal Locomotion, Proceedings of the 2014 Learning and Intelligent Optimization Conference (LION8).
-
- Calandra, R.; Seyfarth, A.; Peters, J.; Deisenroth, M.P. (2014). An Experimental Comparison of Bayesian Optimization for Bipedal Locomotion, Proceedings of 2014 IEEE International Conference on Robotics and Automation (ICRA).
Contact: Elmar Rückert, Jan Peters
Active Perception
A robot needs to be aware of the properties of  objects to efficiently perform tasks with them.
Currently, most robots are provided with this object information by a programmer. However,
autonomous robots working in service industries and domestic settings will need to perform tasks with novel objects. Hence, relying on predefined object knowledge will not be an option.
objects to efficiently perform tasks with them.
Currently, most robots are provided with this object information by a programmer. However,
autonomous robots working in service industries and domestic settings will need to perform tasks with novel objects. Hence, relying on predefined object knowledge will not be an option.
Instead, robots will have to learn about objects by exploring their properties through physical interactions, such as pushing, stroking, and lifting. As random exploration is an inefficient approach, we develop methods for efficiently gathering information.
The fundamental knowledge learned about objects and primitive actions will later on form the basis for learning complex behaviors and predicting the properties of novel objects. By discovering accurate representations of objects, the robot will be able to plan and execute manipulations more precisely.
Learning Tactile Sensing using Vision
The textures of object surfaces can be observed both by visual inspection and by sliding a dynamic tactile sensor across the surface. The robot can combine these types of sensor readings to determine which components of the data contain information pertaining to the texture.
In particular, the robot can find the components that are maximally correlated between the two sensor modalities. Given the relevant data components, the robot can create a compact representation of object textures, which allows it to distinguish between surfaces more accurately.
-
- Kroemer, O.; Lampert, C.H.; Peters, J. (2011). Learning Dynamic Tactile Sensing with Robust Vision-based Training, IEEE Transactions on Robotics (T-Ro), 27, 3, pp.545-557.
Active Learning of Object Properties
Learning about objects is not a passive  perceptual process: its embodiment allows a
robot to discover object properties by actively
changing its point of view and by interacting
with objects. At the same time, the robot
observes the effect of its actions and learns how
it can bring about desired effects.
perceptual process: its embodiment allows a
robot to discover object properties by actively
changing its point of view and by interacting
with objects. At the same time, the robot
observes the effect of its actions and learns how
it can bring about desired effects.
To learn efficiently, the robot should select the exploratory actions that yield the highest information gain out of all possible actions. By efficiently exploring its environment, a robot develops object knowledge grounded in its sensorimotor experience.
The developed object knowledge can be used to manipulate previously unknown objects in unstructured environments. For example, the robot could teach itself to perform tasks in domestic environments.
-
- van Hoof, H.; Kroemer, O; Peters, J. (2014). Probabilistic Segmentation and Targeted Exploration of Objects in Cluttered Environments, IEEE Transactions on Robotics (TRo), 30, 5, pp.1198-1209.
-
- van Hoof, H.; Kroemer, O; Peters, J. (2013). Probabilistic Interactive Segmentation for Anthropomorphic Robots in Cluttered Environments , Proceedings of the International Conference on Humanoid Robots (HUMANOIDS).
Contact: Jan Peters, Gregor Gebhardt
Download: Flyer as PDF
Cognitive Science
Our research on robot skill learning is also connected with the study of the human mind. By increasing our understanding of the way humans learn to perform novel tasks we can discover novel ways for robot learning. Conversely, insights from robot learning may increase our understanding of the human mind. Furthermore, physically connecting the human brain with robots is an important field of research, because it can enable ALS patients and amputees to retrieve physical capabilities.
Biomimetic Robots
Life on earth dates back billions of years and evolved into astonishingly complex organisms by means of natural selection. By understanding how humans and animals are capable of learning how to manipulate their environment we can find inspiration for devising intelligent robot systems.
Modeling Human Motor Learning
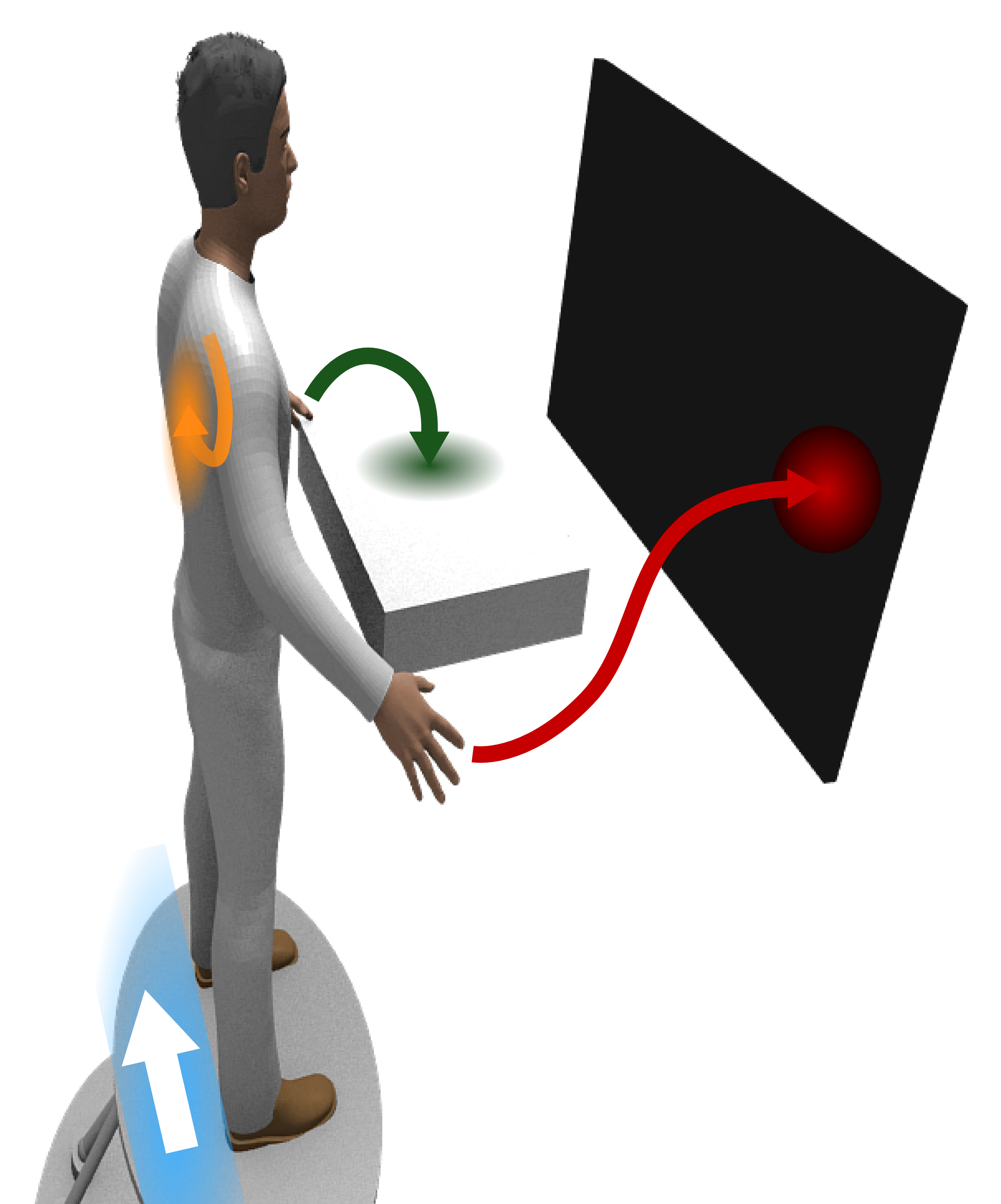
The human central nervous system has an incredible ability for learning new motor skills. For example, when learning to control a novel sport device, new movement and balancing strategies may be discovered within seconds. Such rapid learning processes are based on learned abstract concepts, current beliefs of the environment and future expectations of desired postures, reached targets or achieved rewards (among others). Little is known about how these underlying processes develop and how they interplay during motor learning.
In our research, we develop probabilistic models and inference techniques to gain a better understanding of the amazing human learning abilities. Our models reproduce characteristic features like motor variability, continuous exploration, stochastic decisions and the ability to learn task abstractions. Applications range from medical diagnoses and rehabilitation research to smart robot learning and control frameworks.
-
- Rueckert, E.; Mundo, J.; Paraschos, A.; Peters, J.; Neumann, G. (2015). Extracting Low-Dimensional Control Variables for Movement Primitives, Proceedings of the International Conference on Robotics and Automation (ICRA).
-
- Rueckert, E.; Lioutikov, R.; Calandra, R.; Schmidt, M.; Beckerle, P.; Peters, J. (2015). Low-cost Sensor Glove with Force Feedback for Learning from Demonstrations using Probabilistic Trajectory Representations, ICRA 2015 Workshop on Tactile and force sensing for autonomous compliant intelligent robots.
-
- Rueckert, E.; Camernik, J.; Peters, J.; Babic, J. (2016). Probabilistic Movement Models Show that Postural Control Precedes and Predicts Volitional Motor Control, Nature PG: Scientific Reports, 6, 28455.
Contact: Elmar Rückert, Svenja Stark, Jan Peters
Spiking Neural Networks for Motor Control, Planning and Learning

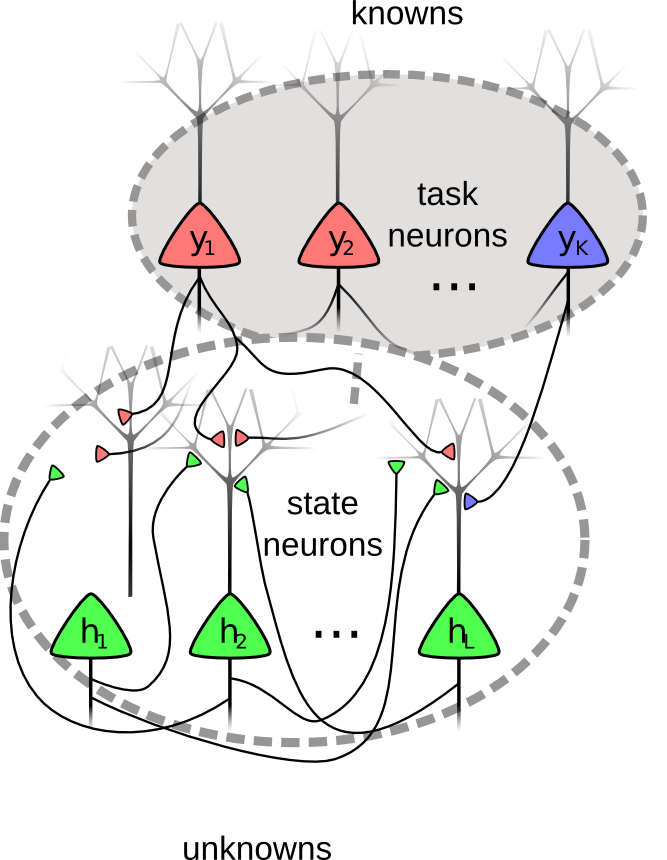
Spiking neural networks are powerful computational models of brain functions and are a key technology in, e.g., the Human Brain Project with estimated total costs of 1.19 billion Euros. A second driving force for intensive research efforts are the massive parallel computing abilities. Companies like IBM, SPS or HP develop 'brain-like' memory and computing chips with the long-term goal of developing neuromorphic computers.
We investigate how spiking neural network models for neuromorphic chips can be used for robot motor control and learning. A strong focus is put on the real-time processing of huge sensory streams from tactile, visual and other sensors and on learning from rewards. The implemented computational principles are based on powerful machine learning algorithms like probabilistic inference, contrastive divergence or stochastic policy search that are used in a large variety of other applications like visual scene understanding, speech processing and cognitive reasoning.
-
- Rueckert, E.; Kappel, D.; Tanneberg, D.; Pecevski, D; Peters, J. (2016). Recurrent Spiking Networks Solve Planning Tasks, Nature PG: Scientific Reports, 6, 21142, Nature Publishing Group.
-
- Tanneberg, D.; Paraschos, A.; Peters, J.; Rueckert, E. (2016). Deep Spiking Networks for Model-based Planning in Humanoids, Proceedings of the International Conference on Humanoid Robots (HUMANOIDS).
-
- Tanneberg, D.; Peters, J.; Rueckert, E. (2017). Efficient Online Adaptation with Stochastic Recurrent Neural Networks, Proceedings of the International Conference on Humanoid Robots (HUMANOIDS).
Contact: Elmar Rückert, Daniel Tanneberg, Jan Peters
Human Motor Control
Insights from control engineering and statistics improve our understanding of how humans work and vice versa. The notions of feedback and information became deeply ingrained in social sciences, following the pioneering work of Norbert Wiener on cybernetics. Creating models of human behaviour based on statistics and control theory that capture certain aspects of cognition and intelligence helps in answering fundamental questions about the subconscious processes taking place in a human being. How do we decide which muscles to activate to move an arm? What makes eyes move to track a moving target? Many such questions can be addressed by means of simplified mathematical models.
Optimal control of ball catching
 Two seemingly contradictory theories attempt to explain how humans move to intercept an airborne ball. One theory posits that humans predict the ball trajectory to optimally plan future actions; the other claims that, instead of performing such complicated computations, humans employ heuristics to reactively choose appropriate actions based on immediate visual feedback. It turns out, interception strategies appearing to be heuristics can be understood as computational solutions to an optimal control problem faced by a ball-catching agent acting under uncertainty.
Two seemingly contradictory theories attempt to explain how humans move to intercept an airborne ball. One theory posits that humans predict the ball trajectory to optimally plan future actions; the other claims that, instead of performing such complicated computations, humans employ heuristics to reactively choose appropriate actions based on immediate visual feedback. It turns out, interception strategies appearing to be heuristics can be understood as computational solutions to an optimal control problem faced by a ball-catching agent acting under uncertainty.-
- Muelling, K.; Kober, J.; Peters, J. (2011). A Biomimetic Approach to Robot Table Tennis, Adaptive Behavior Journal, 19, 5.
-
- Belousov, B.; Neumann, G.; Rothkopf, C.; Peters, J. (2016). Catching Heuristics Are Optimal Control Policies, Advances in Neural Information Processing Systems (NIPS / NeurIPS).
Contact: Jan Peters, Boris Belousov
Brain-Computer Interfaces 
Brain-Computer Interfaces (BCI) can be used to control robots using one's thoughts which can be especially useful for amputees and ALS patients as it allows to control assistive robots or robot prostheses without requiring muscle control. However, classifying the intended actions from BCI sensor data is very challenging, because it is difficult to identify meaningful features of the high-dimensional sensor data. Furthermore, such features are different among patients and typically even vary across different days.
-
- Gomez Rodriguez, M.; Grosse-Wentrup, M.; Hill, J.; Schoelkopf, B.; Gharabaghi, A.; Peters, J. (2011). Towards Brain-Robot Interfaces for Stroke Rehabilitation, Proceedings of the International Conference on Rehabilitation Robotics (ICORR).
-
- Meyer, T.; Peters, J.;Broetz, D.; Zander, T.; Schoelkopf, B.; Soekadar, S.; Grosse-Wentrup, M. (2012). A Brain-Robot Interface for Studying Motor Learning after Stroke, Proceedings of the International Conference on Robot Systems (IROS).
-
- Gomez Rodriguez, M.; Peters, J.; Hill, J.; Schoelkopf, B.; Gharabaghi, A.; Grosse-Wentrup, M. (2011). Closing the Sensorimotor Loop: Haptic Feedback Helps Decoding of Motor Imagery, Journal of Neuroengineering, 8, 3.
Contact: Jan Peters, Filipe Veiga